アルゴリズムRAG開発過程と成果物
GitHubリンク: https://github.com/Hun-Bot2/Algorithm-RAG-Engine
前の記事からの続きです。
Refined後の結果
以前
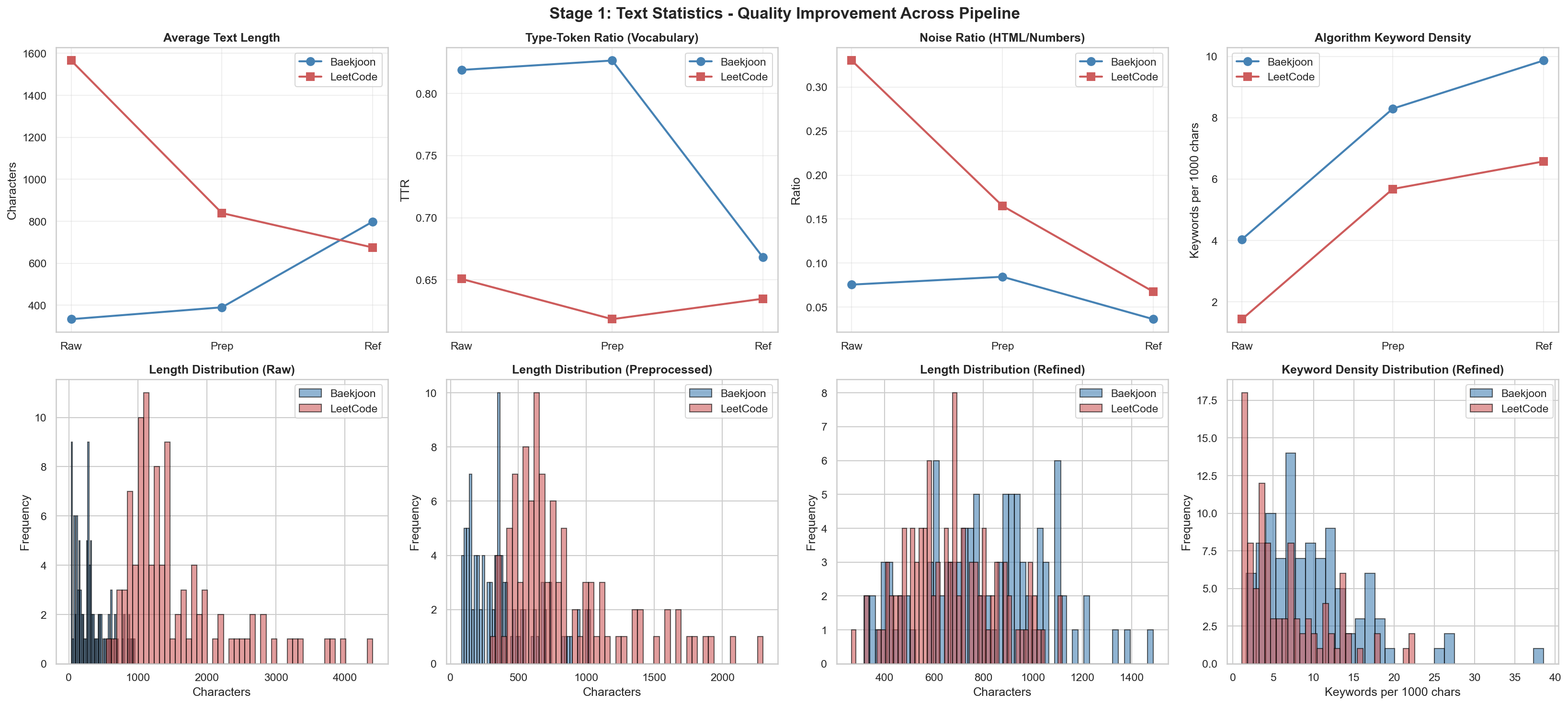
以後
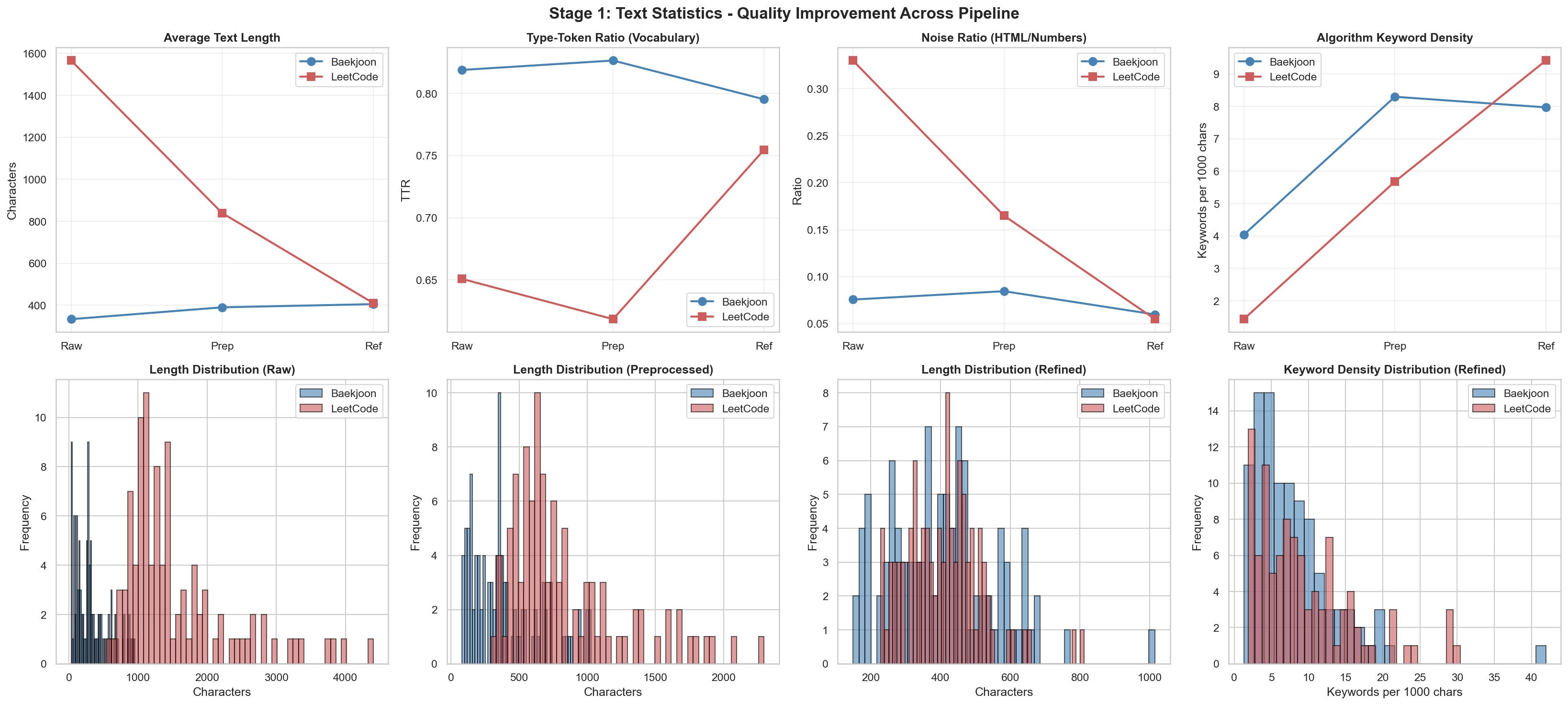
以前
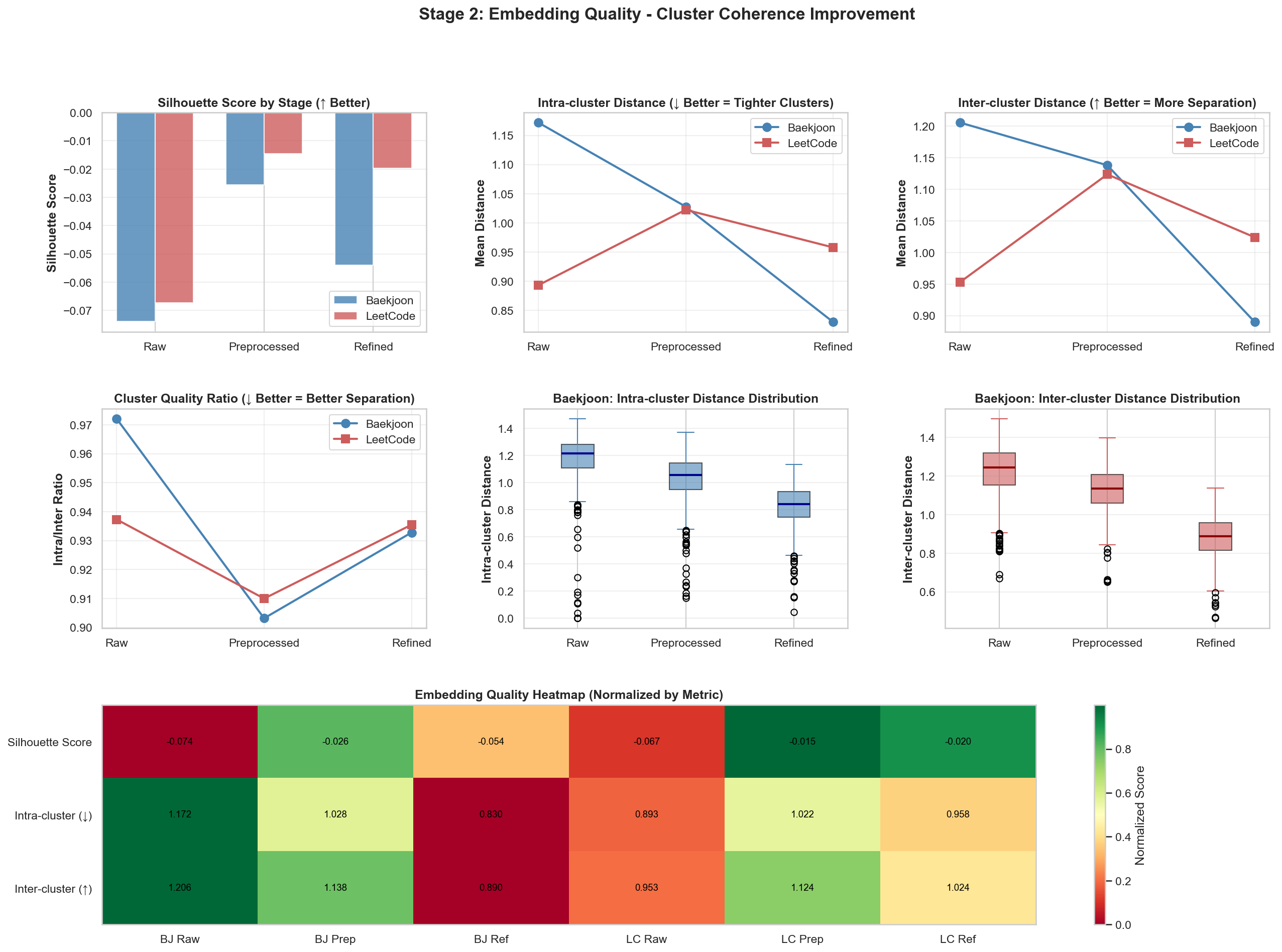
以後
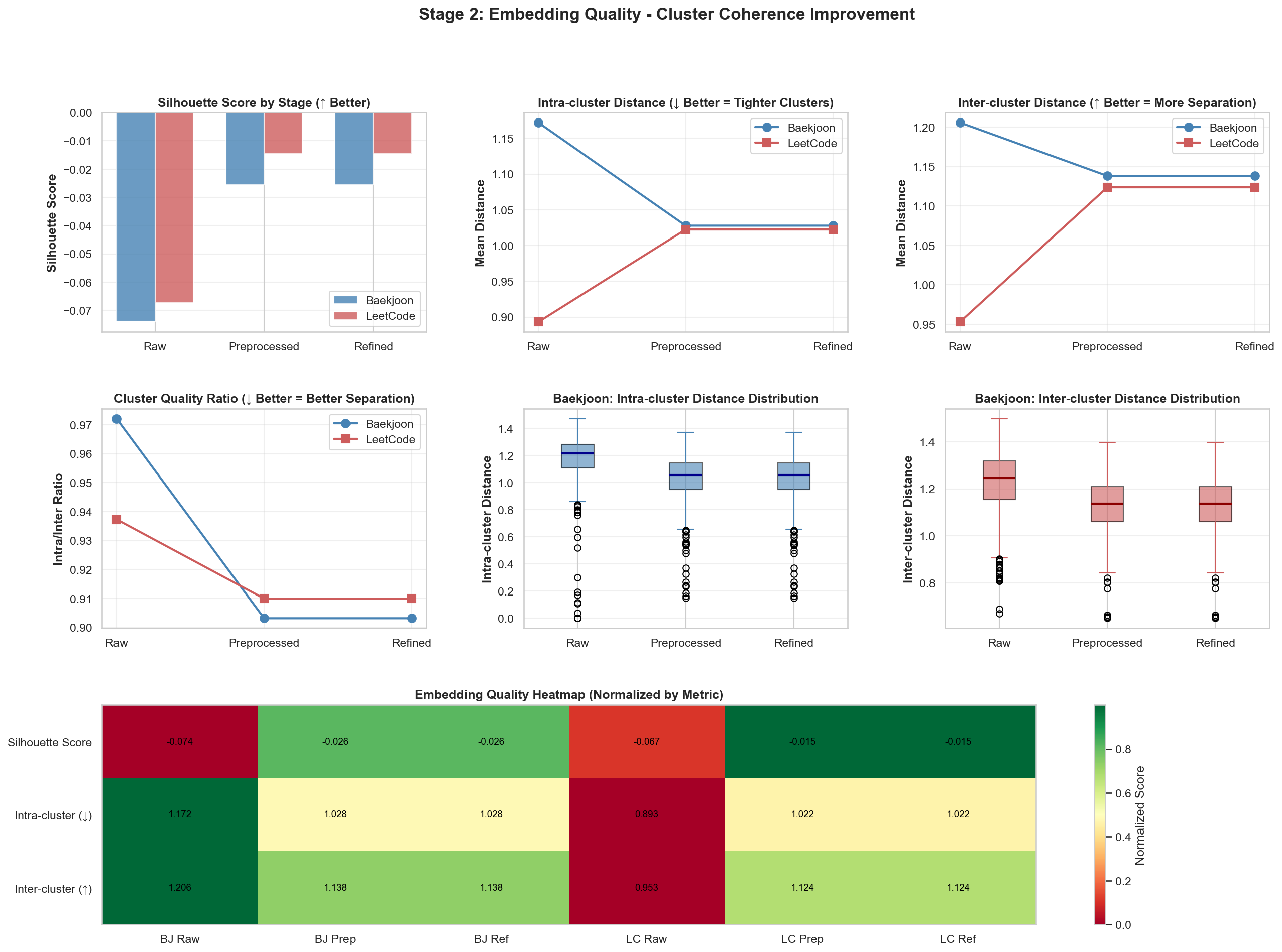
上の2つでは目立つ変化がありました。他の結果値は似たようなものだったので、詳細は該当リポジトリで確認できます。
さて、基本的にembeddingを学習してみたので、実際に3,000個のLeetCode問題を入れてRAGシステムを構築してみます。
LangChain FAISSを活用したRAGシステム
既存計画だったPineconeを活用したRAGシステム構築から方向を変え、LangChainのFAISSを活用したRAGシステムを構築することにしました。
なぜPineconeではなくLangChain FAISSを選んだかというと、LeetCodeの問題数が3,000程度しかないため、Pineconeを使うよりLangChainのFAISSを使うほうが効率的だと考えたからです。
さらに、個人Studyリポジトリに付いていたSlack Botを分離し、RAGリポジトリに統合しました。Monorepoにしようかとも考えましたが、今後の拡張可能性を考慮して別リポジトリとして管理することにしました。
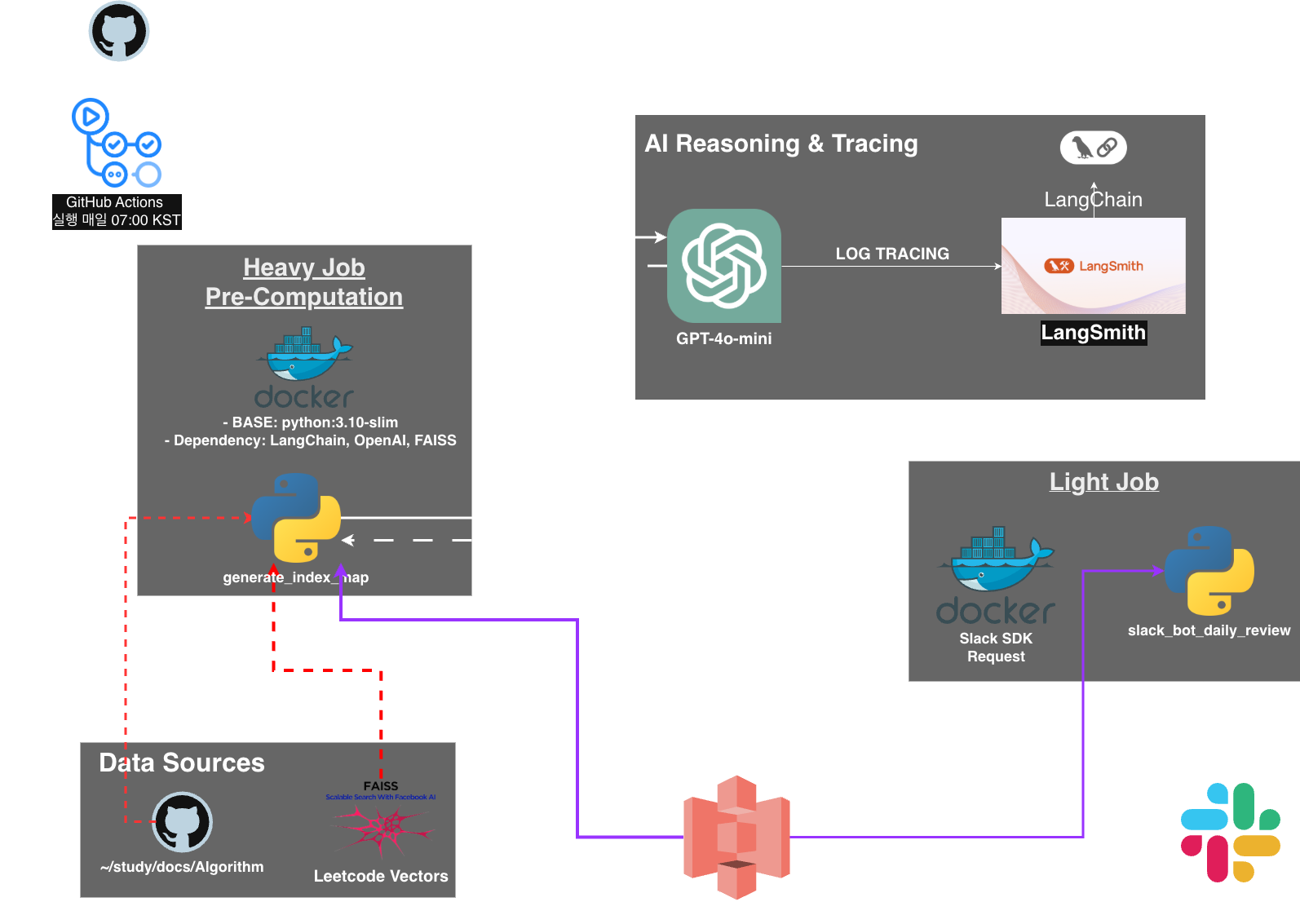
全体アーキテクチャは前の記事で説明し、GitHubリポジトリにも詳しい説明があるため、この記事では**なぜ?**を中心に説明し、私が遭遇した問題を整理していきます。
アーキテクチャは上の通りです。FAISSをどこで使ったのかというと、LeetCode問題を受け取り、埋め込みベクトルへ変換したあと、FAISS Indexに保存し、GitHubリポジトリへPackage形式で上げておきました。Releaseにもあるので参考にしてください。
なぜFAISSを使ったのか?
まず、私が集めたLeetCode問題は約3,000個ほど、無料問題だけでした。問題を保存した形式はJSONLファイルです。当然ですが、LLMがこの問題をすべて読み取って類似問題を探すのは非効率です。 「検索」のためには、これをベクトル化して保存する場所が必要だったため、ローカルvector DBを調べました。
| 区分 | FAISS | ChromaDB | LanceDB |
|---|---|---|---|
| 動作アーキテクチャ | In-memory / Library | SQLiteベースDB | ArrowベースServerless |
| データ規模 | 大規模、10^6以上に最適化 | 小〜中規模に適合 | 中〜大規模に適合 |
| メタデータフィルタリング | 基本機能は弱い(手動実装) | 非常に強力で簡単 | 効率的なフィルタリングを支援 |
| デプロイ容易性 | バイナリファイル1つで完結 | DBファイル構造の管理が必要 | 別ファイル管理が必要 |
| 検索速度 | 最上位(Low-level最適化) | 普通(SQLiteオーバーヘッド) | 高い(Zero-copy読み取り) |
ChromaDB: SQLiteをエンジンとして使うオープンソースのベクトルストアです。Pythonネイティブ環境で非常に使いやすく、メタデータフィルタリング機能が強力です。
LanceDB: Apache Arrow形式をベースにしており、「サーバーレス(Serverless)」を志向します。ディスクIO効率が非常に高いため、データが大きくなっても性能低下が少ないです。
FAISS (Facebook AI Similarity Search): Meta、旧Facebookが開発した高性能類似度検索ライブラリです。DBというよりアルゴリズムライブラリに近く、メモリ内検索速度が圧倒的です。
データが少ないのに、なぜFAISSを使ったのか?
- LangChainを勉強している途中で使ってみたかったからです。ブログ3編を参考にしてください。
- GitHub Actionsに適したベクトルDBが必要で、FAISSは単純なライブラリ形態としてインデックスファイル(
.faiss)だけ管理すればよかったからです。 - 構築済みの問題は追加頻度が低く、一度構築しておけばRead中心で使います。そのため速度の速いFAISSを選びました。
なぜS3をアーティファクト保存所にしたのか? (vs GitHub Artifacts)
問題: GitHub Actions自体にもファイルを保存する機能、Artifactsがあります。それなのになぜAWS S3を使ったのでしょうか。
- データ永続性: GitHub Artifactsは一定期間、基本90日後に削除されますが、S3は永続保管できます。
- 作業間のデカップリング: Heavy JobとLight Jobの実行環境を物理的に分離し、システムの柔軟性を確保しました。 S3を中間媒体として活用し、データを受け渡す過程の結合度を下げることで、各作業が互いの状態に依存せず独立して実行できる構造が必要でした。
- 外部拡張性: 後でSlack以外にWebダッシュボードなどを作る場合にも、S3のデータをAPIで直接読み込める拡張性を考慮しました。
Decoupling Heavy & Light Jobs
- Heavy Job: LeetCode問題を収集し、埋め込みベクトルを生成したあと、FAISSインデックスを構築します。この作業は時間がかかり、頻繁には実行されません。
- Light Job: FAISSインデックスを読み込み、類似問題を検索し、類似問題とLLMが生成した理由をSlackへ送信します。この作業は頻繁に実行され、速い応答が必要です。
変更事項
アルゴリズムを解いてコミットすると、設定しておいた復習周期ごとに通知が来る構造でした。しかし、毎日2〜3問の学習と2〜3問の復習をすると仮定すると、1日目は2問 + 2問、2日目にまた問題を解くと2問 + 2問、3日目には合計6問 + 2問の学習になり、正直処理しきれないと判断して復習周期を削除しました。
そして次の形へ変更しました。
-
Trigger: 今日、または昨日に問題を解いてコミットしたときだけ動作。
-
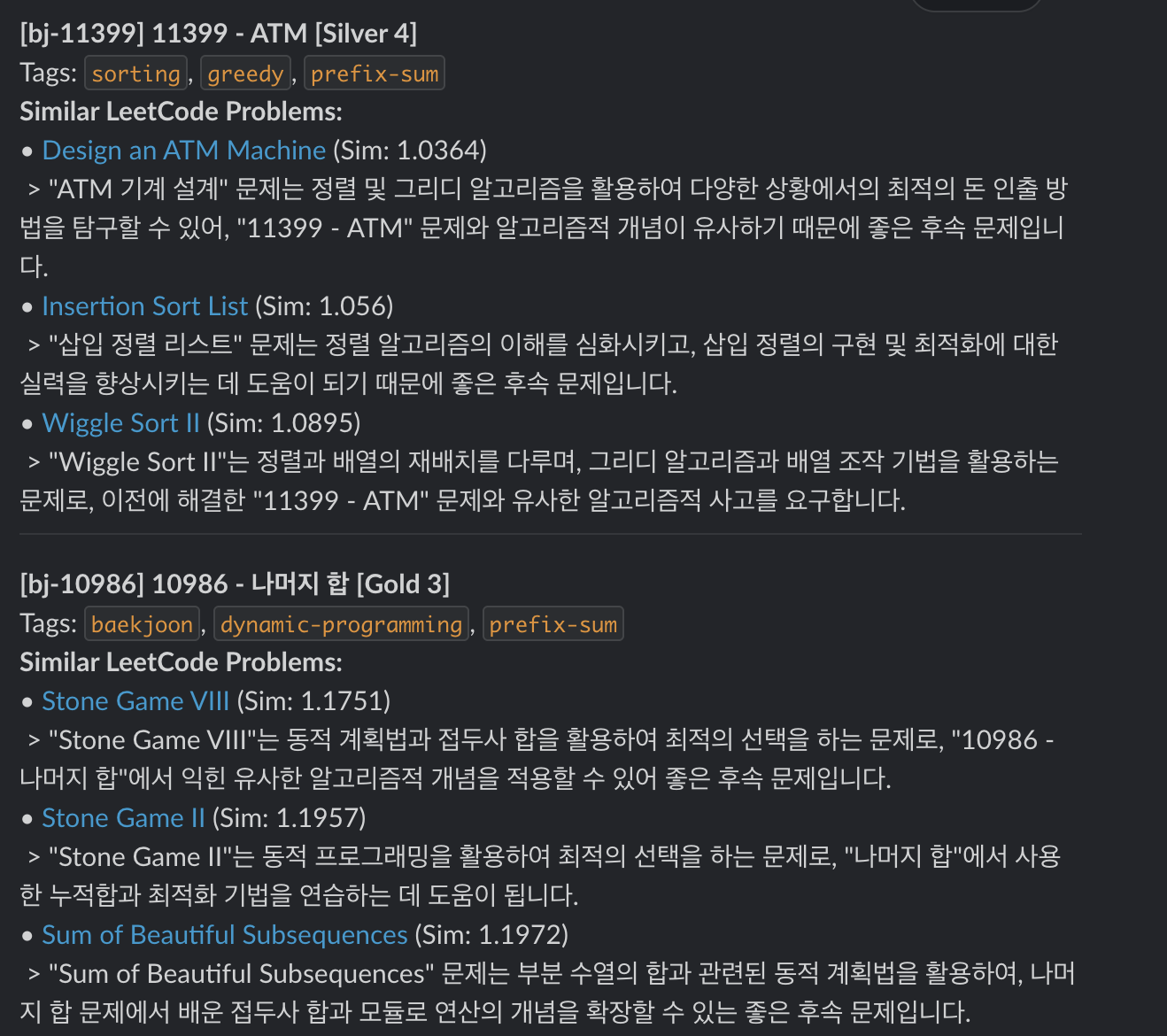
Action: 「自分が今解いたこのBaekjoon問題」と最も似ているLeetCode問題を推薦。
-
Goal: 学習した概念を別プラットフォーム、LeetCodeの問題へ適用して体化することへ目標を変更。
該当リポジトリの最新コミットだけを取得するGitPython導入
構造上、毎回すべてのファイルを取得するのは非効率なので、最新コミットで変更されたファイルだけを取得するようにしました。
def get_latest_changed_files(repo_path: str, target_subdir: str) -> List[str]:
"""
Detects files changed in the latest commit (HEAD) within the target subdirectory.
"""
print(f"[INFO] Checking git history in: {repo_path}")
changed_files = []
try:
repo = Repo(repo_path)
# Ensure we have commits to compare
if not repo.head.is_valid():
print("[WARN] No valid HEAD found (empty repo?). Scanning all files.")
return get_all_files(repo_path, target_subdir)
head_commit = repo.head.commit
# If no parents (first commit), scan all files in the tree
if not head_commit.parents:
print("[INFO] First commit detected. Scanning all files.")
for item in head_commit.tree.traverse():
if item.path.startswith(target_subdir) and item.path.endswith((".md", ".mdx")):
full_path = os.path.join(repo_path, item.path)
changed_files.append(full_path)
else:
# Compare HEAD with HEAD~1 (Previous commit)
parent = head_commit.parents[0]
diffs = parent.diff(head_commit)
for diff in diffs:
# We only care about added (A) or modified (M) files
# diff.b_path is the new path. If deleted, it might be None or verify deleted_file flag
if diff.b_path and not diff.deleted_file:
if diff.b_path.startswith(target_subdir) and diff.b_path.endswith((".md", ".mdx")):
full_path = os.path.join(repo_path, diff.b_path)
changed_files.append(full_path)
except Exception as e:
print(f"[ERROR] Git processing failed: {e}")
print("[INFO] Falling back to scanning all files.")
return get_all_files(repo_path, target_subdir)
return changed_filesLeetCode問題同士を重複して取得しないPythonロジックを追加
# Search
search_limit = MAX_RECOMMENDATIONS + 2 # Buffer to avoid self-match
docs_and_scores = vectorstore.similarity_search_with_score(
user_prob["query_text"],
k=search_limit
)
recs = []
# Avoid Duplicates & Self-Match
seen_title= set()
user_title_clean=re.sub(r'[^a-zA-Z0-9가-힣]', '', user_prob["title"].lower())
for doc, score in docs_and_scores:
if len(recs) >= MAX_RECOMMENDATIONS:
break
rec_title=doc.metadata.get("title", "Unknown")
rec_title_clean=re.sub(r'[^a-zA-Z0-9가-힣]', '', rec_title.lower())
if user_title_clean in rec_title_clean or rec_title_clean in user_title_clean:
continue # Skip self-match
if rec_title_clean in seen_title:
continue # Skip duplicates
seen_title.add(rec_title_clean)
...通知(実際の応答)
おわりに
これでアルゴリズムRAGシステムの構築が完了しました。今回のプロジェクトを通じて、ベクトル検索技術とRAGシステムの実際の適用方法を理解できました。
ここに追加する部分は、おそらく次の1〜4番程度になると思います。
- 初期環境変数設定なしで使えるようにする。
- 他の人も使える形で構築する。
- 構築したLeetCode問題を成長する木の形で可視化する。問題を解くと木が成長し、解いた問題は光る葉になり、難易度ごとに別の色で表現する。
- グラフネットワーク可視化。
今後、自分で使いながら継続的にシステムを改善し、より多くの問題を追加して、アルゴリズム学習に役立つツールへ発展させていきます。ありがとうございました。
댓글