
アルゴリズムRAG開発過程とモデル性能比較
前の記事からの続きです。
Architecture
以前考えていた全体の流れです。

本格的な開発に入る前に、勉強も兼ねて埋め込みモデルを比較してみることにしました。
思ったより時間がかかった作業で、自分の分析が正しいのかも確信できないため、コミュニティで検証してもらう予定です。もしこの記事を読まれた方がいれば、フィードバックをいただけるとありがたいです。
データ収集と前処理 (Data Acquisition and Preprocessing)
-
LeetCode: LeetCode GraphQL APIを通じて、2025年基準の全問題セット(約3,500問以上)。
-
Baekjoon: solved.ac APIおよびWebクローリング。
それぞれ100件のデータを収集し、埋め込み性能を最大化するために次の前処理を行いました。
-
HTMLおよびノイズ除去: HTMLタグと不要な叙述表現を整理しました。
-
検索最適化テキスト構成: Title、Tags、Contentを結合し、モデルが問題のカテゴリと制約条件を明確に認識できるように
embedding_textフィールドを生成しました。 -
Logical Skeleton: AIがこの言葉をかなり好みます。問題の核心となるアルゴリズム論理を要約した
logical_skeletonフィールドをLLMで生成しました。Baekjoonは韓国語ベースなので、英語に翻訳した内容を入れました。
1. データ収集 (Data Collection)
├─ baekjoon_data_collection.py → baekjoon_raw_data.jsonl (100個)
└─ leetcode_data_collection.py → leetcode_raw_data.jsonl (100個)
2. データ前処理 (Preprocessing)
├─ preprocess.py → *_preprocessed.jsonl
│ └─ HTML/Markdown除去、核心ロジック抽出
└─ refine_leetcode.py → leetcode_refined.jsonl
└─ LLMベースの論理骨格(Logical Skeleton)抽出
3. データ正規化 (Normalization)
├─ improve_recall.py → baekjoon_refined.jsonl
│ └─ Baekjoonデータも英文の論理骨格へ変換
└─ data_normal.py → baekjoon_normalized.jsonl
└─ 接頭辞("Logical Skeleton: ")除去 -> "embedding_text"へ変換
4. Ground Truth構築 (GT Creation)
├─ ground_truth_finder.py → potential_gt.json
│ └─ LLMで候補を自動抽出して検収
└─ leetcode_match_pgt.py → ground_truth_v2.json
└─ 100セットのBJ-LC正解ペアを完成
5. モデル評価 (Model Benchmarking)
├─ evaluate_model.py → OpenAI text-embedding-3-small
├─ evalute_model_ver2.py → Jina-v3 (1024 dim)
└─ evalute_model_ver3.py → BGE-M3 (Local)
└─ Recall@K, MRR測定なぜ100個だけなのか?
Ground Truthを100個作成したため、ランダムに100個ずつ選んで実験を行いました。一般的にはGolden Setのように呼ぶようです。これは人が直接マッピングする必要があるそうです。
埋め込みモデル比較と検証 (Embedding Model Benchmark)
より精密な知識マッピングのため、3つの主要な埋め込みモデルを対象に性能検証、つまりパイロットテストを行いました。
比較モデル: Jina v3、OpenAI text-embedding-3-small、BGE-M3。
評価指標 (Metrics)
- Recall@K: 上位K件の結果の中に正解が含まれる割合。
- MRR (Mean Reciprocal Rank): 正解が現れた順位の逆数の平均。
ベンチマーク結果(100-Set Golden Set基準)
| Model | Recall@1 | Recall@5 | Recall@10 | MRR |
|---|---|---|---|---|
| OpenAI-v3 (small) | 0.22 | 0.50 | 0.65 | 0.354 |
| Jina-v3 (1024 dim) | 0.17 | 0.47 | 0.63 | 0.319 |
| BGE-M3 (Local) | 0.15 | 0.40 | 0.53 | 0.272 |
OpenAI-v3 (small)モデルが最も優れた性能を示しました。
Recall@10: 正解候補を10位以内にはよく取得できていますが、Recall@1: 1位に正解を当てる比率は相対的に低く、22%でした。
ここで終われればよかったのですが…
実はこの結果を見た後も、どこかすっきりしない感じがありました。 自分が作ったデータは3種類、[Raw, Preprocessed, Refined]ですが、これだけでよいのだろうかという疑問が残りました。
そこで、自分が行った過程全体を分析することにし、次の追加実験を行いました。
データ保存形式は.jsonlにしました。
[1] Text Statistics: Length, TTR, noise ratio, keyword density
[2] Embedding Quality: Intra/inter-cluster distances, Silhouette Score
[3] t-SNE & UMAP
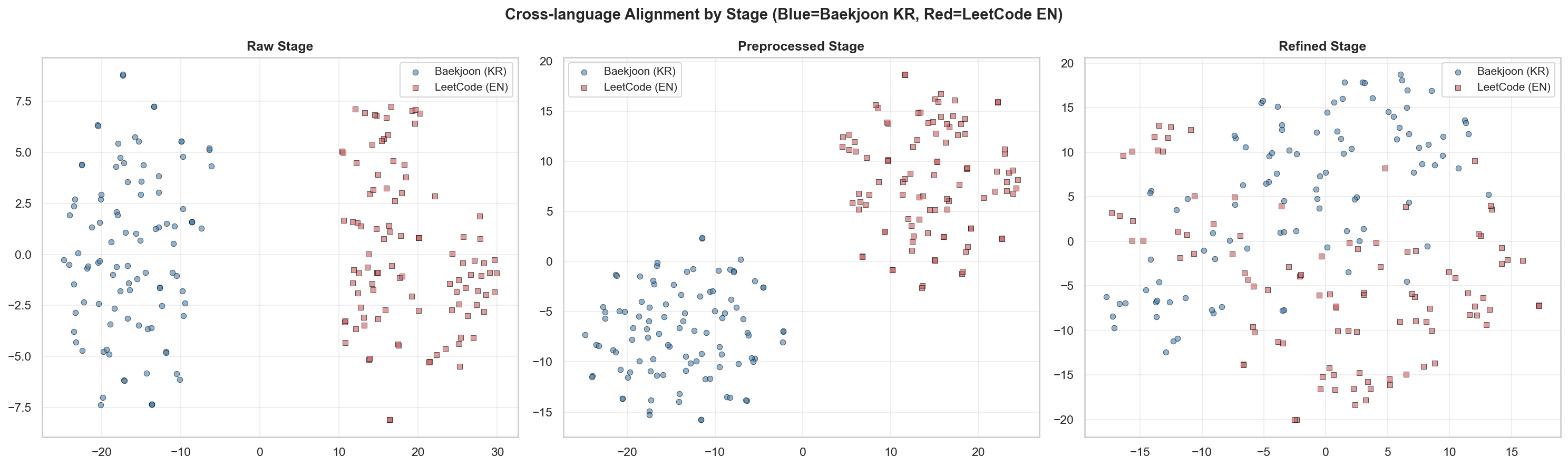
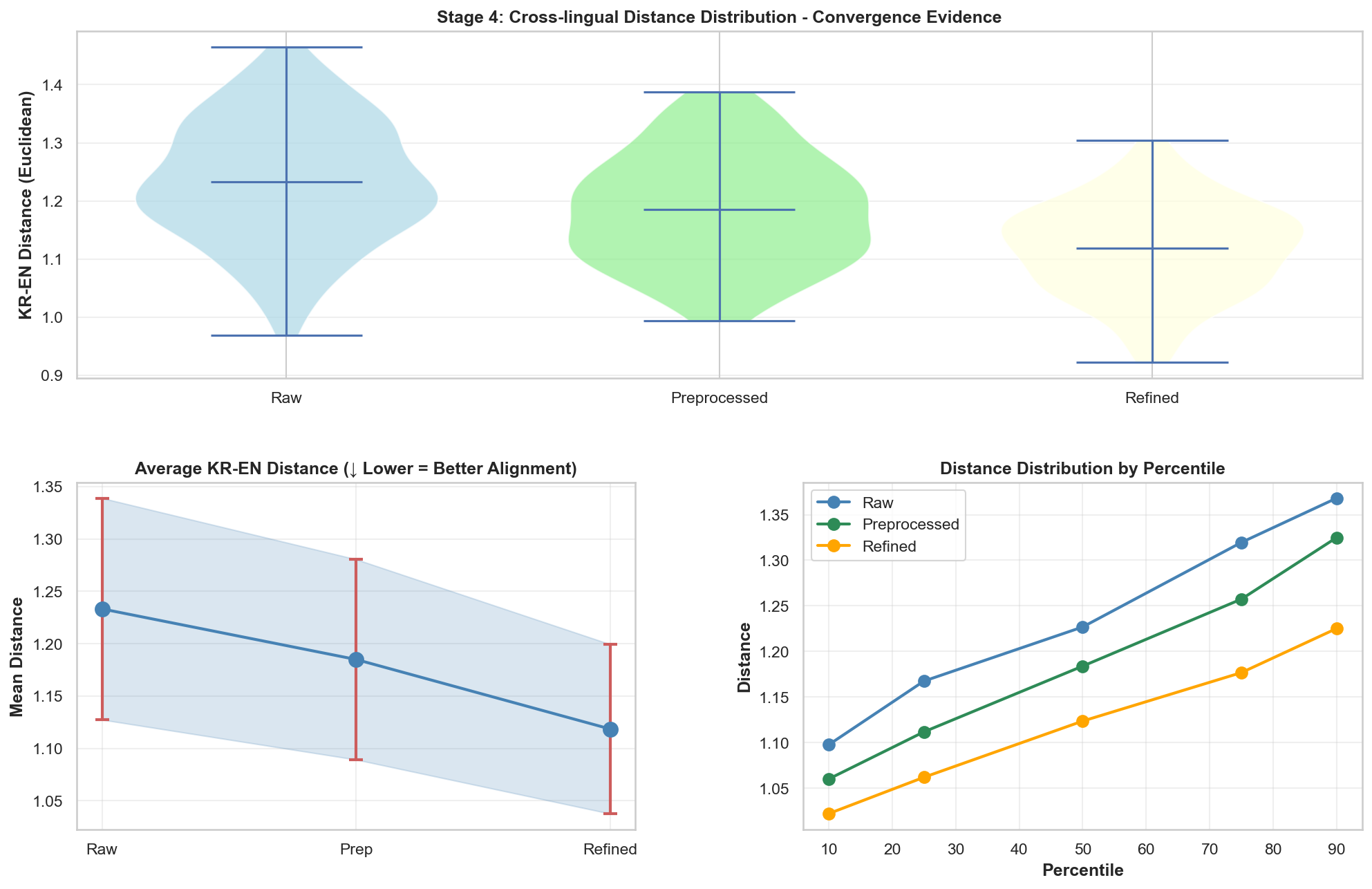
[4] Cross-lingual Alignment: KR <-> EN
[1] Text Statistics
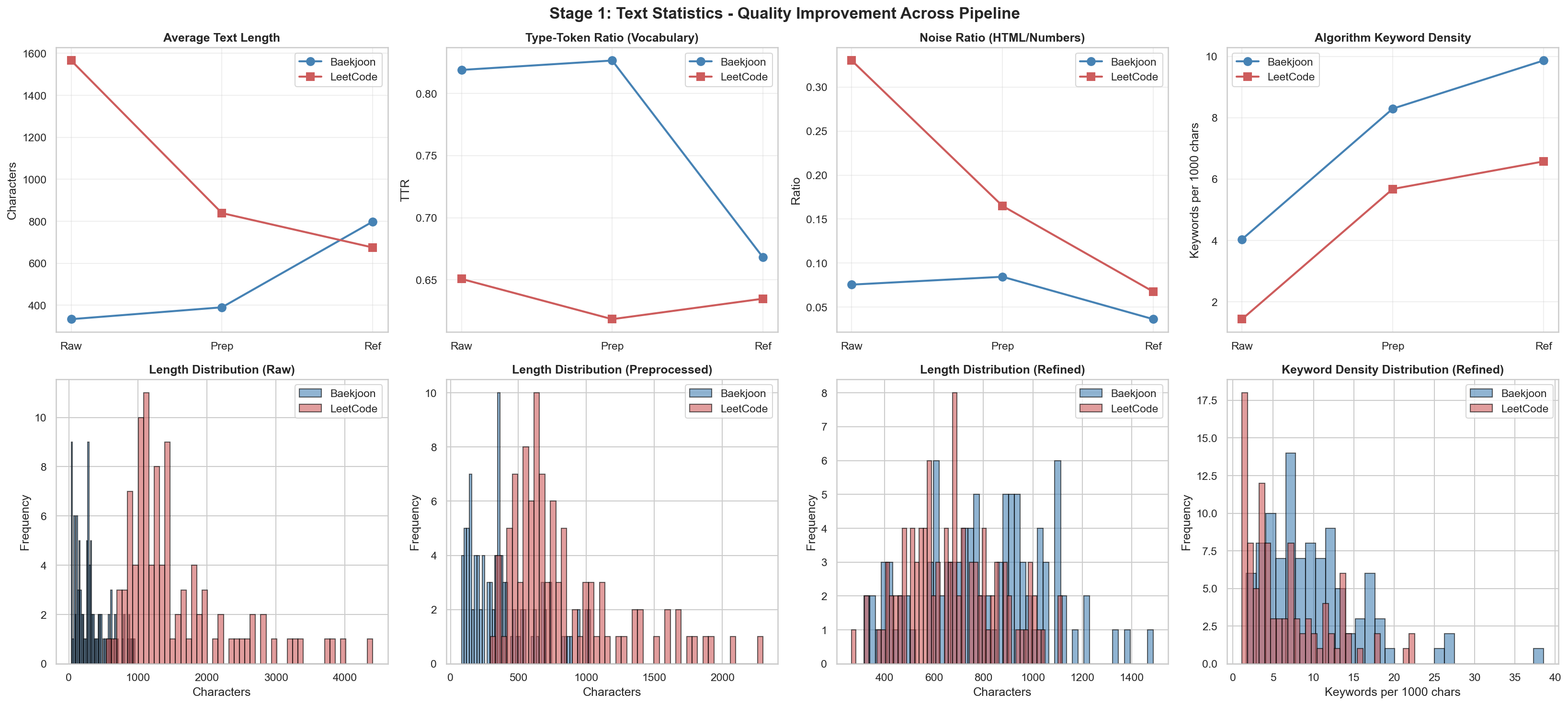
HTML Noiseの部分で差が出る理由は何でしょうか。 LeetCodeはGraphQL APIを通じてそのまま取得するロジックを使いました。
{"id": "14", "title": "Longest Common Prefix", "titleSlug": "longest-common-prefix", "difficulty": "Easy", "content": "<p>Write a function to find the longest common prefix string amongst an array of strings.</p>\n\n<p>If there is no common prefix, return an empty string <code>""</code>.</p>\n\n<p>&n"}Baekjoonはsolved.ac APIを通じて取得しました。
{"id": "9251", "title": "LCS", "difficulty": 11, "tags": ["dp", "string", "lcs"], "content": "LCS(Longest Common Subsequence, 최장 공통 부분 수열)문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다.예를 들어, ACAYKP와 CAPCAK의 LCS는..."}BaekjoonにはHTMLタグがほとんどないため、ノイズ比率が低く出たようです。そのため、同じ前処理コードを回したとき、むしろBaekjoonデータが少し改善する現象が発生したのではないかと推測しています。
[2] Embedding Quality
Jina-v3とOpenAI-v3 (small)モデルで、各ファイルごとに埋め込みを生成しました。 使用量はそれほど大きくありませんでした。
BAEKJOON DATASETS:
Raw: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Preprocessed: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Refined: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
LEETCODE DATASETS:
Raw: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Preprocessed: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Refined: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']Silhouette Score
K-Meansのようなクラスタリングアルゴリズムでデータをグループ化するとき、そのグループがうまく分類されたか確認する方法の一つです。
値は-1から1までを取ります。私のプログラムの目的は、Baekjoon問題からLeetCode問題をうまくマッチングすることなので、Baekjoon問題同士の距離が、Baekjoon問題とLeetCode問題間の距離より大きくなる状態を目指します。そのため、この設定では負の値が出るほうがよいです。
- (Intra-cluster distance): 自分が属するクラスタ内の他データとの平均距離です。
- (Inter-cluster distance): 自分が属していない最も近いクラスタとの平均距離です。
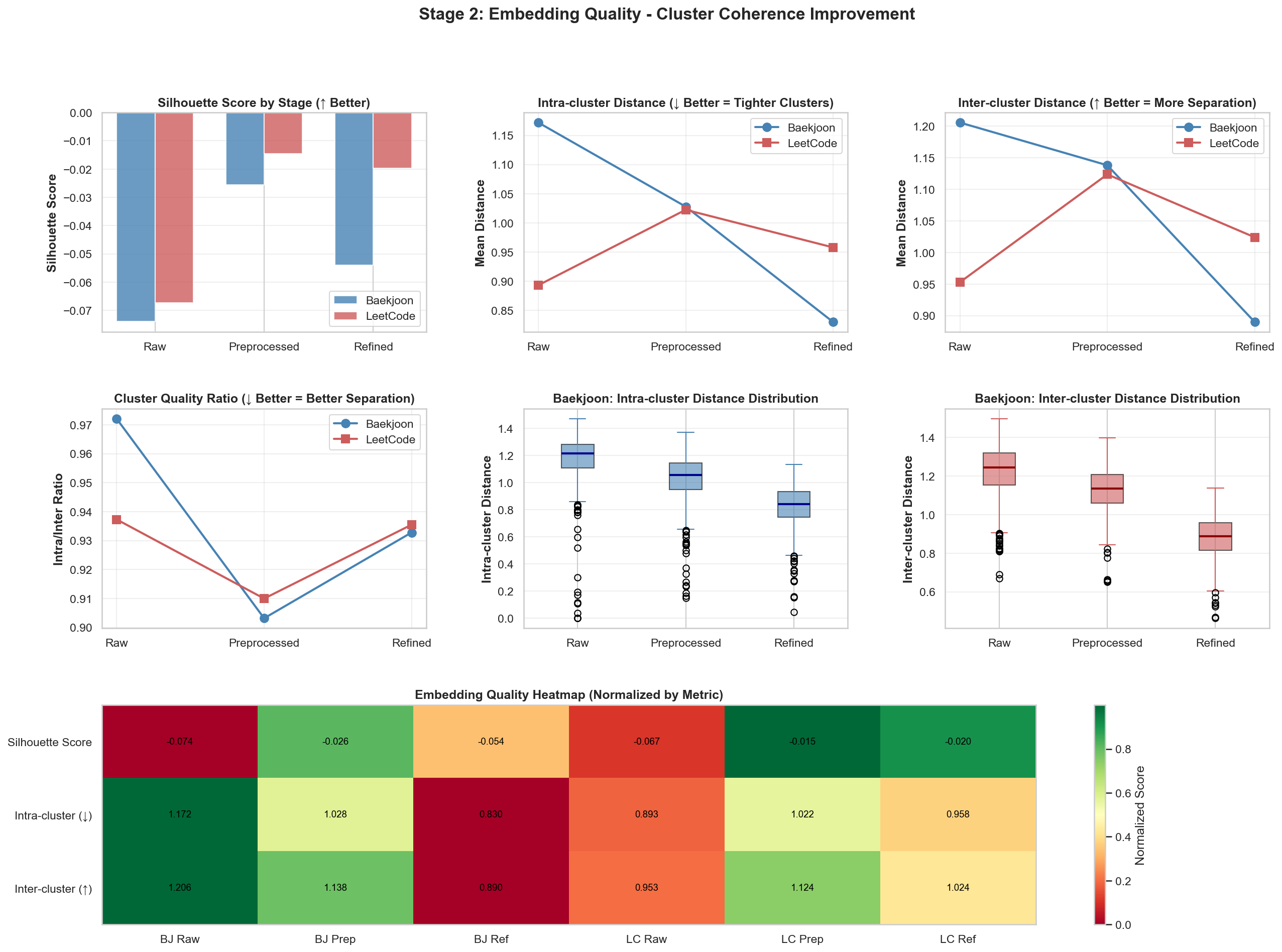
1. Silhouette Score
RawからPreprocessedへ進むときに最も大きな向上があり、Refinedへ進むとむしろ低下しました。これは前処理過程が埋め込み品質に最も大きな影響を与えたことを示しています。
2. Intra-cluster Distance(クラスタ内距離)
クラスタ内部のデータ同士がどれだけ近いかを測定します。値が低いほど、同じカテゴリの問題がベクトル空間上で密に集まっているという意味です。
Baekjoon(青色)はRawからRefinedへ進むほど距離が急激に減少します。これは精製過程を経て、Baekjoon問題がより一貫したベクトル表現を持つようになったことを意味します。一方、LeetCodeはPreprocessedでピークを示したあと、再び低くなる傾向を見せます。
3. Inter-cluster Distance(クラスタ間距離)
異なるクラスタ、つまりBaekjoonグループとLeetCodeグループの間の距離を測定します。値が高いほど、2つのグループが明確に区別されるという意味です。
Baekjoonは段階が進むほど距離がむしろ減っており、これはBaekjoonデータがLeetCodeデータのベクトル領域へ少しずつ近づいていることを示唆します。つまり、2つのプラットフォーム間の「意味的距離」が狭まっていると解釈できると思います。
4. Cluster Quality Ratio (Intra/Inter Ratio)
クラスタ内距離 / クラスタ間距離の比率です。この値が低いほど理想的です。
両データセットともPreprocessed段階で最小点、つまり最も良い品質を示します。その後Refined段階で少し上昇するのは、過度な精製がデータ固有の特徴を一部薄めた可能性を示しています。
5. Distance Distribution (Box Plots)
Baekjoonデータの距離分布を可視化したものです。中央値、箱の中の線、データの広がりを見ることができます。
Intra-cluster: 段階が進むほど箱の高さが低くなり、位置も下がります。これは極端な外れ値なしにデータが均一に密集していることを意味します。
Inter-cluster: 外部との距離分布も下方向に安定し、他データセットとの比較が可能な範囲に入っています。
6. Embedding Quality Heatmap
すべての指標を総合して可視化した表です。緑色に近いほど、その指標で優れた性能を示していることを意味します。
**BJ Prep(Baekjoon前処理)**とLC Prep(LeetCode前処理)の列で緑色の比重が最も高いです。
結果として、現在のデータセットでは「Preprocessed」状態の埋め込みが検索効率として最も高い、という統計的結論を出せます。
このような結果になったため、Refined段階で何が問題だったのか確認しました。
やはり、AIがあれほど強調して好んでいたBaekjoonデータセットのembedding_textをLogical Skeletonへ置き換えたことが、むしろ悪影響になったようです。LeetCodeデータとは形式が異なるため、ベクトル空間で遠ざかってしまったのではないかと推測しています。
解決: アルゴリズム開発記 04
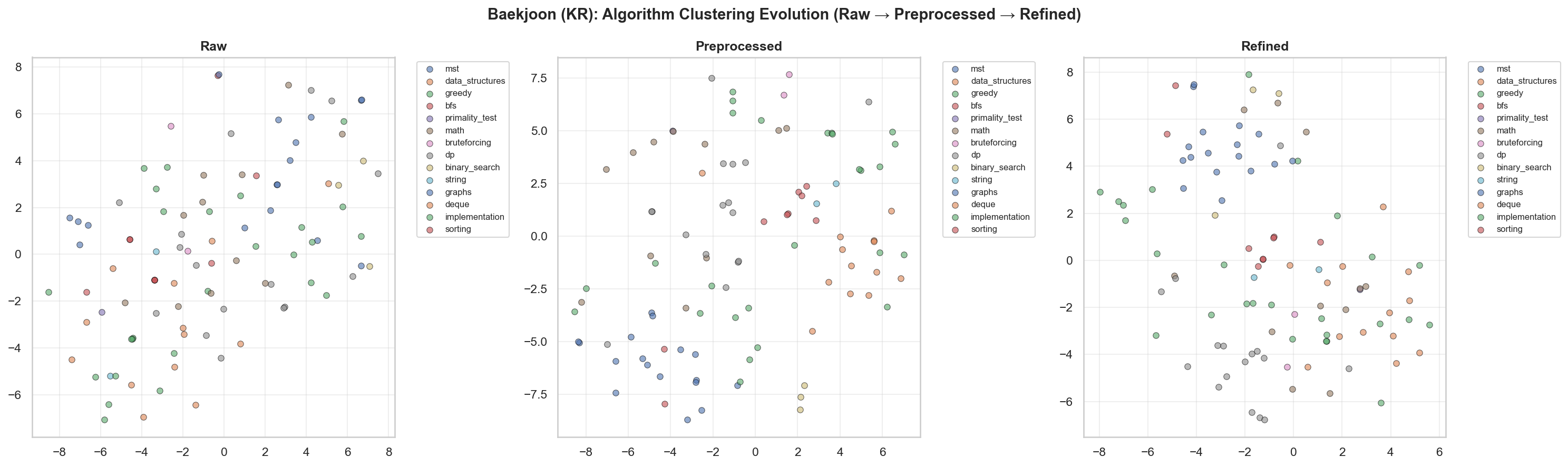
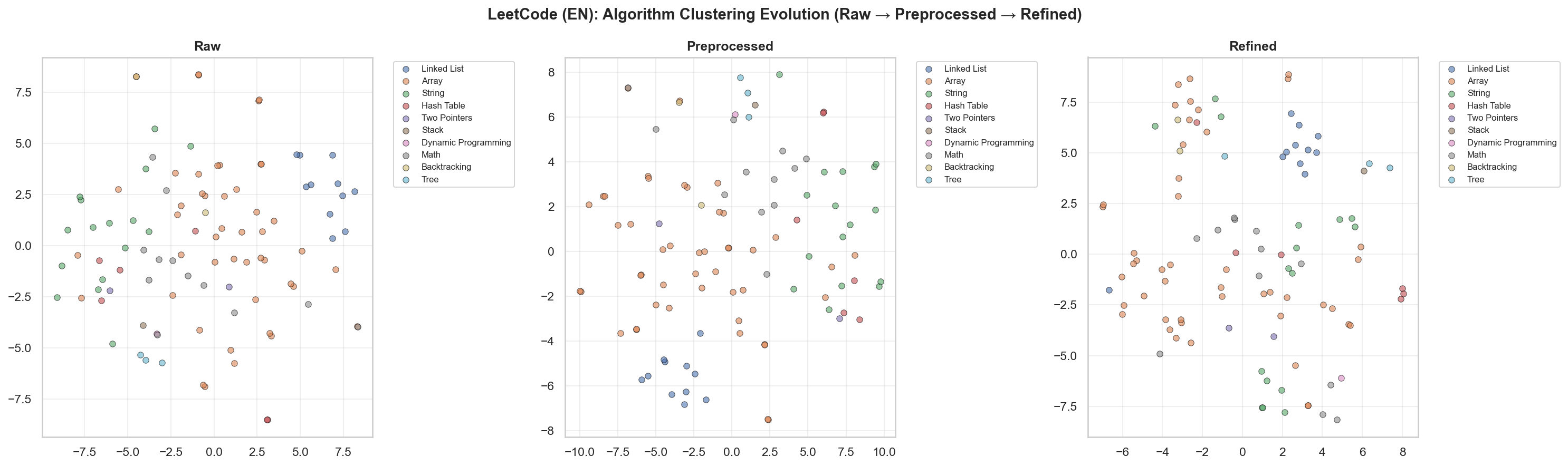
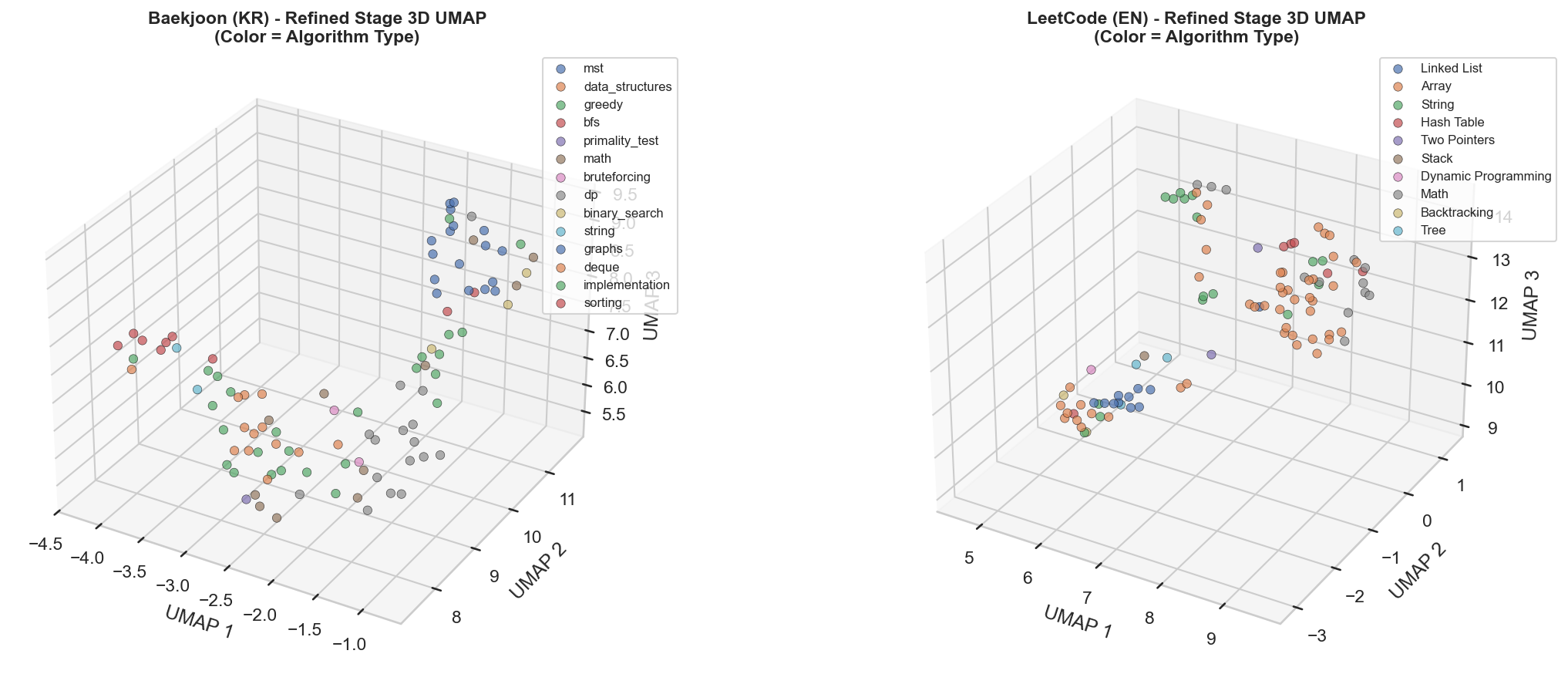
[3] t-SNE & UMAP
Baekjoon問題 t-SNE可視化
LeetCode問題 t-SNE可視化
韓国語 -> 英語 前処理過程
UMAP可視化(Refinedデータセット)
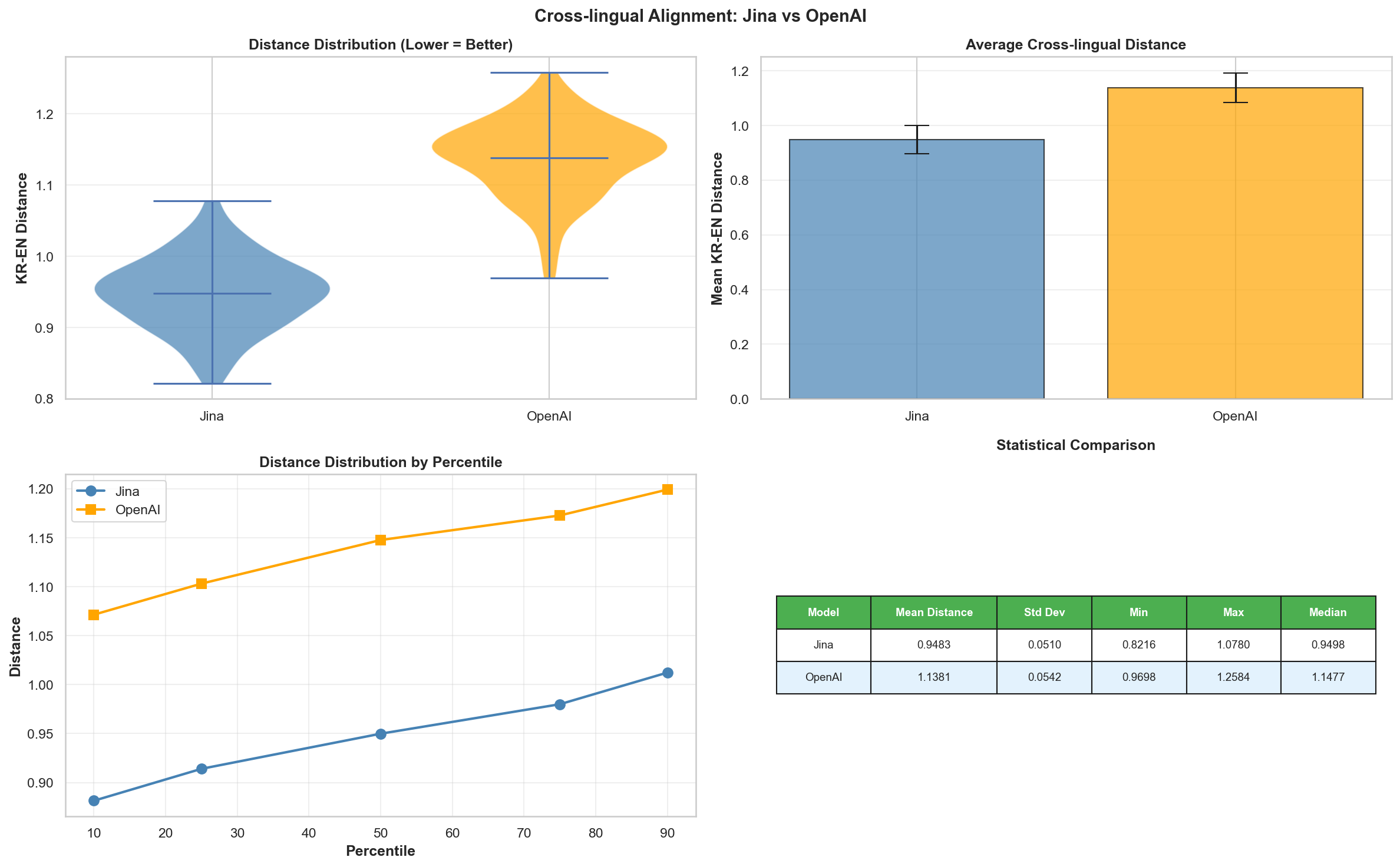
[4] Cross-lingual Alignment
Jina v3 vs OpenAI text-embedding-3-small
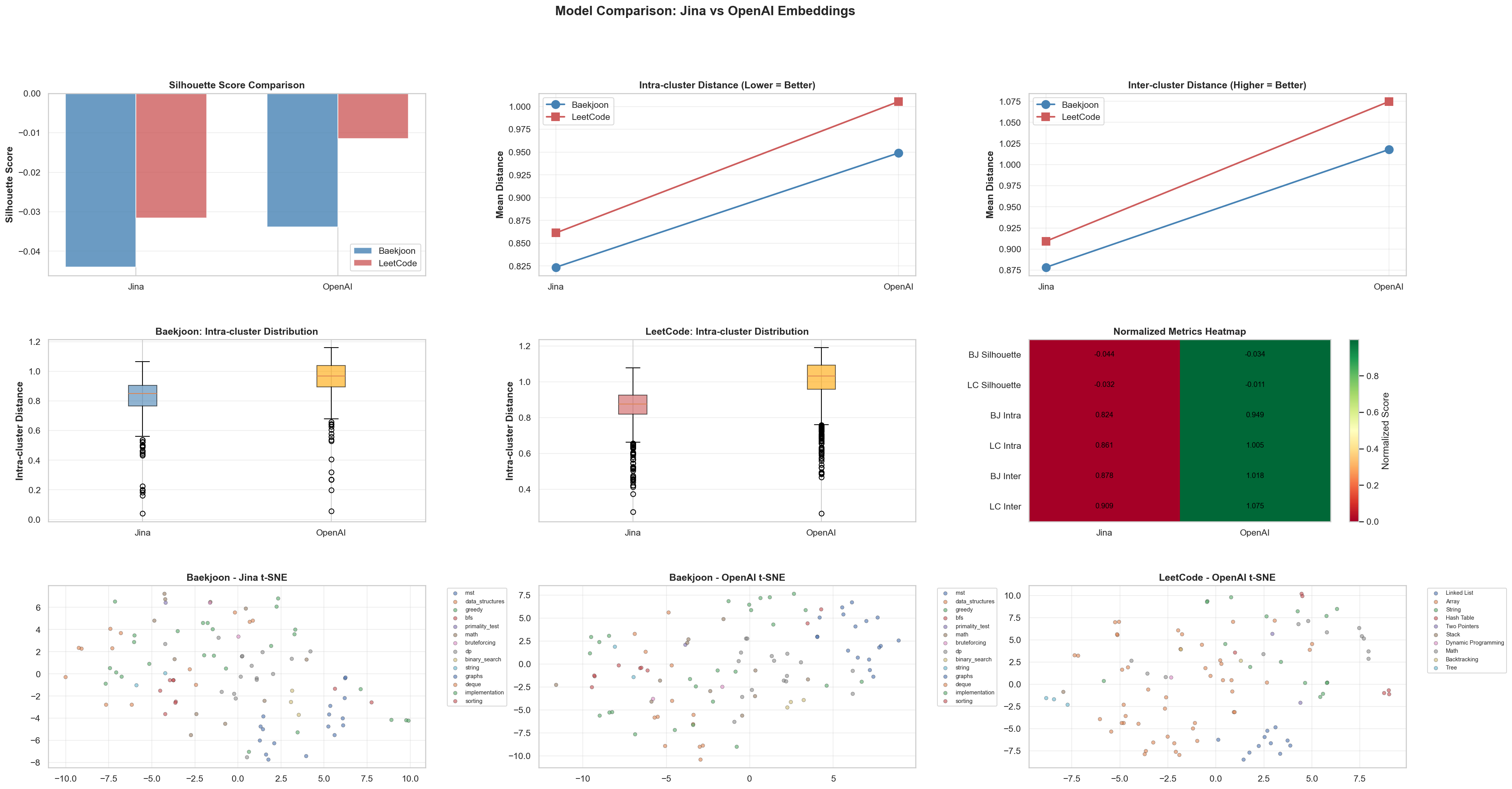
上で行った前処理過程と分析をもとに、Jina v3とOpenAI text-embedding-3-smallモデルの性能差を比較しました。
OpenAIモデルが全体的により良い性能を示したため、今後のアプリ開発ではOpenAIモデルを採用することにしました。
結論と次の段階
今回の埋め込みモデル比較とデータ前処理分析を通じて、次の結論を得ました。
- OpenAI text-embedding-3-smallモデルはJina v3より優れた性能を示した。
- データ前処理過程は埋め込み品質に大きな影響を与える。
- Refined段階での過度な精製は、むしろ性能低下を招く可能性がある。
まずはRefined段階からlogical skeletonを除去し、2つのデータセットを同じ形式にそろえた後、もう一度ベンチマークを回してみる予定です。
[Algorithm Type] {Algorithm Name}
[Problem Summary] {Core logic description}
[Complexity] Time: {Time}, Space: {Space}
댓글