Local LLM 개발일지 01
참고 글 : *블로그 개발일지 07 - Local LLM을 활용한 블로그 글 자동 번역 기능*
개요
로컬에서 실행되는 대형 언어 모델(Local LLM)을 활용하여 블로그 글을 자동으로 번역하는 기능을 개발하고 있습니다. 기존 블로그 글에 작성되어 있지 않은 구현 부분의 영역을 기록하고, 오류를 수정하는 과정을 기록하려고 합니다.
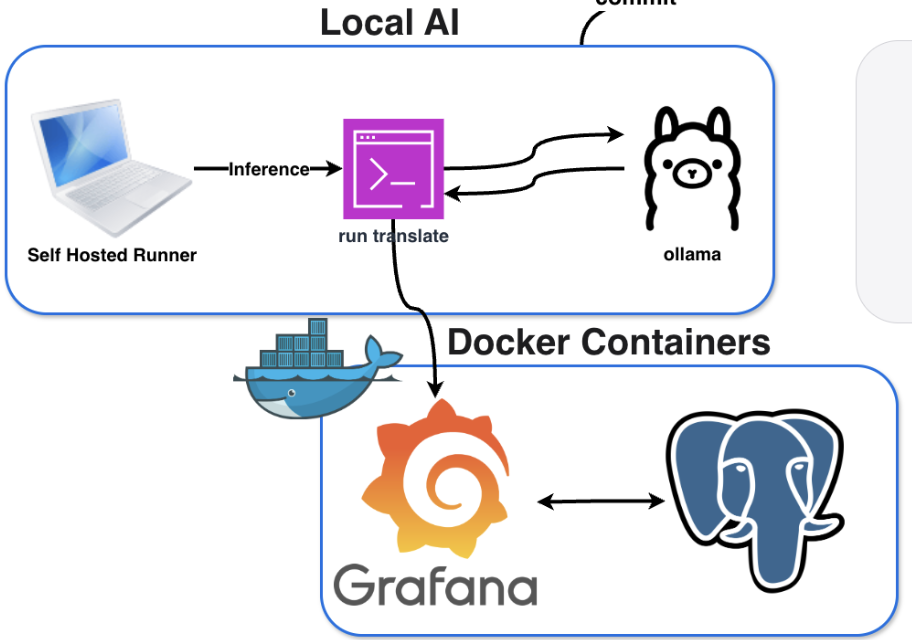
프로젝트 구조
local-llm-observability
├─ LICENSE
├─ README.md
├─ database
│ └─ init.sql
├─ docker-compose.yml
├─ requirements.txt
└─ src
├─ main.py
├─ monitor_agent.py
└─ translation_agent.py이렇게 구분이 되어 있고, translation_agent.py 파일이 블로그 글 번역과 관련된 핵심 로직이 담겨 있습니다.
SQL
CREATE TABLE IF NOT EXISTS translation_logs (
id SERIAL PRIMARY KEY,
timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
model_name VARCHAR(50),
source_lang VARCHAR(10),
target_lang VARCHAR(10),
input_length INT,
output_length INT,
latency_ms FLOAT,
tokens_per_sec FLOAT,
similarity_score FLOAT,
input_text TEXT,
output_text TEXT
);
CREATE INDEX idx_model ON translation_logs(model_name);
CREATE INDEX idx_timestamp ON translation_logs(timestamp);초기 실험
블로그에 작성되어 내용처럼 만들고 돌렸는데, 번역 퀄리티와 Frontmatter Format, 번역을 하지 못하는 단어들, 이상한 내용들이 나와서, 그런 부분들을 해결하기 위해 우선 LLM 모델이 어디를 어려워하는지 보려고 합니다.
문서에서 키워드 뽑아내기
순서는 아래와 같습니다.
- 기존 한국어 블로그를 읽고 Ollama 모델이 어려워 하는 단어나 문장을 뽑아내는 작업을 한다.
- glossary.json에 기록을 한다. (왜 SQL에 기록하지 않은지 -> 그렇게 많지도 않고, 데이터가 바뀌지 않기에 굳이 DB에 넣을 필요가 없다고 판단)
- 해당 기록을 바탕으로 번역을 시도한다.
아래는 제가 작성하는 블로그 Frontmatter 구조입니다.
---
title: '블로그 개발일지 07'
description: 'Local LLM을 활용한 블로그 글 자동 번역 기능'
pubDate: '2026-02-07'
heroImage: '/images/BLOG/blog-arch-v2.png'
tags: ['Local LLM', '자동 번역', '블로그']
category: 'blog_devlog'
series: '블로그 개발일지'
seriesOrder: 7
---반나절 이상 붙잡고, 계속해서 실험을 하고 있는데, 알고리즘 봇 개발기 시리즈에서 3번,4번 글을 번역에 어려움을 겪는 문제가 있었습니다.
마크다운 형식의 표가 깨지고, ```이 태그 사이에 있는 코드 블록이 이상하게 변형, 마크다운 형식 자체를 못 잡거나, 띄어쓰기가 이상하거나 등등 여러 문제가 있었고, 이걸 어떻게 해결할지가 고민을 했었는데, 돈이 많으면 그냥 Claude와 같은 초대형 모델을 사용해 번역하는게 좋을 것 같다라는 생각이 들더라구요;;
저는 돈이 없기에.. Hugging face에 있는 오픈 모델중에서 2가지 모델로 테스팅을 해봤는데, 하나는 Qwen2.5:14b와 다른 하나는 facebook/nllb-200-distilled-600M 모델로 테스팅을 했습니다.
결과는 다음과 같습니다. 본문이 길어 부분만 발췌했습니다.
원본
## 왜 만들려고 하는가?
기존에 구축한 에빙하우스 망각 곡선 기반의 Slack 알림 봇은 **이미 푼 문제**를 다시 들여다보게 하는 데는 성공적이었습니다.
하지만 장기 기억으로 유지하고, 알고리즘의 실력을 늘리기 위해서는 풀었던 유형에 대한 **변형 문제 풀이**나**같은 유형의 문제 풀이**가 있어야 하기에
복습할 당시, 제가 복습할 문제를 AI에게 던져서 "이것과 유사한 문제를 찾아줘"라는 방식으로 유사한 문제를 풀었고, 이 부분을 자동화하려고 합니다.제 일본어 실력이 미흡해서, 일본인으로써 어색한 표현까지는 잡아내지 못합니다..
Qwen2.5:14b 모델 번역 결과
## なぜ作ろうとしているのか?
これまでに構築したエbbinghausの忘却曲線に基づいたSlack通知BOTは、**既に解いた問題を再検討する**という点では成功しました。しかし、長期的な記憶に維持し、アルゴリズムのスキルを向上させるためには、解決済みの形式に対する**変形問題の解法**や**同様の形式の問題の解法**が必要です。
そのため、復習する際はAIに対して「この問題と似た問題を見つけて」というように類似した問題を探し、これを自動化しようと考えています。 오류 목록
에빙하우스, 알림 -> 통지, 이미 푼 문제 -> 既に解いた問題 까지만 해야하는데, 그 뒤까지 강조 표현을 사용
nllb-200-distilled-600M 모델 번역 결과
## なぜ作ろうとしているのか?
しかし,長期記憶を保ち,アルゴリズムの効率性を高めるために,解決されたタイプの問題について,変数式問題解決法や,解決されたタイプの問題解決法のような問題解決法が必要だと考えるとき,私は AIに復習する問題を投げ出し,類似の問題を"これのような問題を探す"という方法で解決し,この部分を自動化しようとしています.오류 목록
하지만이 먼저 나옴, 에빙하우스가 없음, 쉼표가 지나치게 많음, 변수식문제해결(???) 뭔 이상한 단어가, 문제 해결법과 같은 문제 해결법(???)
이런 저런 오류가 있었지만, 제 개인적인 느낌을 살려주는 건 Qwen2.5:14b 모델이 더 낫다는 느낌이 들었습니다. 위에 글은 쉬운 글에 대한 비교였고, 아래는 문장 형태가 복잡해졌을 때, 응답입니다.
원문
## 데이터 수집 및 전처리 (Data Acquisition and Preprocessing)
* **LeetCode :** Leetcode GraphQL API를 통해 2025년 기준 전체 문제셋(약 3,500개 이상)
* **Baekjoon :** solved.ac API 및 웹 크롤링
각각 100개의 데이터를 수집했고, 수집된 데이터는 임베딩 성능을 극대화하기 위해 다음과 같은 전처리 과정을 거쳤습니다.
* **HTML 및 노이즈 제거:** HTML 태그와 불필요한 서술어를 정제했습니다.
* **검색 최적화 텍스트 구성:** Title, Tags, Content를 결합하여 모델이 문제의 카테고리와 제약 조건을 명확히 인지할 수 있도록 `embedding_text` 필드를 생성했습니다.
* **Logical Skeleton:** (AI가 이 말을 겁나게 좋아합니다) 문제의 핵심 알고리즘 논리를 요약한 `logical_skeleton` 필드를 LLM을 활용해 생성했습니다(백준은 한국어 기반이기에 영어로 번역한 내용을 담았습니다)
```text
1. 데이터 수집 (Data Collection)
├─ baekjoon_data_collection.py → baekjoon_raw_data.jsonl (100개)
└─ leetcode_data_collection.py → leetcode_raw_data.jsonl (100개)
2. 데이터 전처리 (Preprocessing)
├─ preprocess.py → *_preprocessed.jsonl
│ └─ HTML/마크다운 제거, 핵심 로직 추출
└─ refine_leetcode.py → leetcode_refined.jsonl
└─ LLM 기반 논리 골격(Logical Skeleton) 추출
3. 데이터 정규화 (Normalization)
├─ improve_recall.py → baekjoon_refined.jsonl
│ └─ 백준 데이터도 영문 논리 골격으로 변환(여기서 Logical Skeleton 태그가 달림)
└─ data_normal.py → baekjoon_normalized.jsonl
└─ 접두사("Logical Skeleton: ") 제거 -> "embedding_text"로 변환
4. Ground Truth 구축 (GT Creation)
├─ ground_truth_finder.py → potential_gt.json
│ └─ LLM으로 후보 자동 추출하고 검수
└─ leetcode_match_pgt.py → ground_truth_v2.json
└─ 100세트 BJ-LC 정답 쌍 완성
5. 모델 평가 (Model Benchmarking)
├─ evaluate_model.py → OpenAI text-embedding-3-small
├─ evalute_model_ver2.py → Jina-v3 (1024 dim)
└─ evalute_model_ver3.py → BGE-M3 (Local)
└─ Recall@K, MRR 측정Qwen2.5:14b 모델 번역 결과
## データ収集および前処理 (Data Acquisition and Preprocessing)
* **LeetCode:** Leetcode GraphQL API を利用し、2025年時点の全問題セット(約3,500問以上)
* **Baekjoon:** solved.ac API とウェブスクレイピング
それぞれ100件のデータを収集しました。収集したデータは埋め込み性能を最大化するために以下の前処理を行いました。
* **HTMLおよびノイズ除去:** HTMLタグや不要な記述語を取り除きました。
* **検索最適化用テキスト構成:** Title, Tags, Content を組み合わせ、モデルが問題のカテゴリと制約条件を明確に理解できるように `embedding_text` フィールドを作成しました。
* **論理的スケleton:** (AIにとってこの説明が大好きです) 問題の核心的なアルゴリズム論理を要約した `logical_skeleton` フィールドをLLMを使用して生成しました(Baekjoonは韓国語ベースであるため、英訳された内容を含んでいます)
1. データ収集 (Data Collection)
├─ baekjoon_data_collection.py → baekjoon_raw_data.jsonl (100件)
└─ leetcode_data_collection.py → leetcode_raw_data.jsonl (100件)
---
データ前処理(Preprocessing)
├─ preprocess.py → *_preprocessed.jsonl
│ └─ HTML/マークダウンの削除、核心ロジック抽出
└─ refine_leetcode.py → leetcode_refined.jsonl
└─ LLMベース論理構造(Logical Skeleton)抽出
データ正規化(Normalization)
├─ improve_recall.py → baekjoon_refined.jsonl
│ └─ バージョン英語の論理構造に変換(ここで"Logical Skeleton"タグが付く)
└─ data_normal.py → baekjoon_normalized.jsonl
└─ 接頭辞("Logical Skeleton: ")削除 -> "embedding_text"へ変換
Ground Truth構築(GT Creation)
├─ ground_truth_finder.py → potential_gt.json
│ └─ LLMによる候補の自動抽出と審査
└─ leetcode_match_pgt.py → ground_truth_v2.json
└─ 100セットBJ-LC正解ペア完成
モデル評価(Model Benchmarking)
├─ evaluate_model.py → OpenAI text-embedding-3-small
├─ evalute_model_ver2.py → Jina-v3 (1024 dim)
└─ evalute_model_ver3.py → BGE-M3 (ローカル)
└─ Recall@K、MRR測定
---
この翻訳では、「データ前処理」から「モデル評価」までのプロセスと各ステップの詳細なタスクを日本語に翻訳しました。技術用語や特殊文字はそのまま維持し、日本語テクノロジーブログスタイルに合わせた表現を使用しています。
오류 목록
우선, 제일 아래 제가 작성하지 않은 설명이 붙음, 나머지는 표현이 조금씩 이상한 부분이 존재하지만, 크게 벗어나지 않음
facebook/nllb-200-distilled-600M 모델 번역 결과
##データ収集・事前処理
* **LeetCode:** Leetcode GraphQL APIを介して2025年までには,全体の問題集 (約3,500個以上) を設定しています.
* **Baekjoon:** solved.ac APIとウェブクロール
それぞれ100個のデータを収集し,集めたデータは,埋め込み性能を最大限に高めるために以下の処理を行いました.
**HTMLとノイズ削除:** HTMLタグと不必要な語彙を削除しました.
* **検索最適化テキスト構成:** タイトル,タグ,コンテンツを組み合わせ,モデルが問題のカテゴリーと制限条件を明確に認識できるように `embedding_text`フィールドを作成しました.
**Logical Skeleton:** (AIはこれを好む) ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ ヽ 1.データ収集 (Data Collection) ─baekjoon_data_collection.py →baekjoon_raw_data.jsonl (100個) ─leetcode_data_collection.py →leet_raw_data.jsonl (100個)
2.データ処理 (Preprocessing) ─preprocess.py → *_preprocessed.jsonl │ ─ HTML/マークダウン削除,コアロジック抽出 ─refine_leetcode.py → leetcode_refined.jsonl ─LLMベースの論理骨格解剖(Logical Skeleton)抽出
3.データ正規化 (Normalization) ─ improve_recall.py → baekjoon_refined.jsonl │ ─ 백준データも英語の論理骨格に変換される (Logical Skeleton タグが表示されている場所) ─ data_normal.py → baekjoon_normalized.jsonl ─頭蓋骨は"Logical Skeleton: ") を削除する -> "embedding_text"に変換する
4. Ground Truth 構築 (GT Creation) ─ ground_truth_finder.py → potential_gt.json │ ─ LLMで候補者を自動抽出して検定する─leetcode_match_pgt.py → ground_truth_v2.json ─100セット BJ-LC 正式双式完成
5.モデル評価 (Model Benchmarking) ─ evaluate_model.py → OpenAI text-embedding-3-small ─ evalute_model_ver2.py → Jina-v3 (1024 dim) ─ evalute_model_ver3.py → BGE-M3 (Local) ─ Recall@K,MRR測定 ```
Ground Truthを100個作っていたので,ランダムに100個ずつ抽出して実験を行いました.通常はGloden Set (グロデンセット) と呼ばれていました.これは人間が自分でマッピングする必要があるとされています.
오류 목록
형식이 깨졌고, 문장이 없어짐, 번역의 이상한 부분이 보임
결론
“알고리즘 봇” 시리즈 5편 번역을 시켜봤는데, 두 모델 모두 만족스럽지 않았습니다. Qwen2.5:14b 모델이 낫긴 했지만, 그래도 완벽하지는 않았습니다.
그냥 클로드를 결제해서 썼다면, 이렇게까지 시간이 많이 소요되지 않았을텐데, 로컬 LLM을 활용하다보니, 이런저런 문제들이 많이 발생하는 것 같습니다. 그래도 언젠간 도움이 될 것 같아서 꾸역꾸역 진행을 해 봤습니다.
우선, 로컬 모델을 실행하면 제 맥북이 매우 뜨거워져서, GPU 서버를 구매해서 거기서 돌릴 예정입니다. Local LLM을 돌리면서 얻어낸 prompt나 데이터베이스에 있는 특정 단어의 번역 셋이나 그렇게 모아둔 자료들을 정리해서 GPU 서버 같이 올려서 번역을 실행시킨다면 꽤 좋은 퀄리티의 번역이 나오지 않을까 기대하고 있습니다.
다음 글에는 번역 퀄리티를 높이기 위해 구축한 glossary database 및 아키텍쳐 수정안에 대해서 작성해보도록 하겠습니다. 감사합니다!
댓글