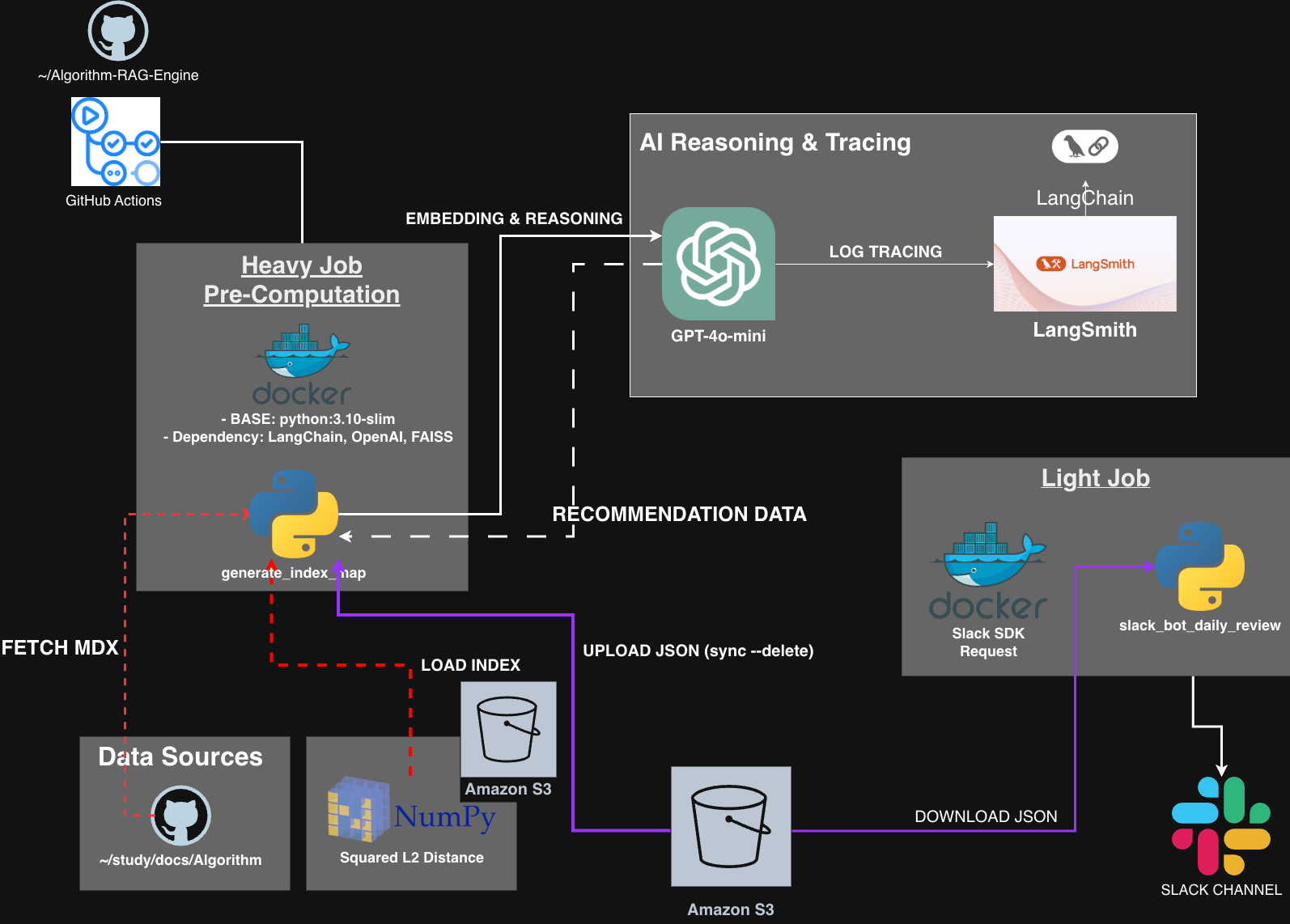
알고리즘 RAG 수정
algorithm RAG LangChain automation
이전 글에서 이어집니다.
FAISS 제거 및 Numpy 계산 도입
앞서 작성한 글에서 LangChain의 FAISS를 활용한 RAG 시스템을 구축했다고 얘기했는데, 공부할 겸 뜯어보다가 FAISS를 사용할 이유가 없었음을 깨닫고, 단순 Numpy 계산으로 유사도 검색을 수행하는 것이 더 효율적이기에 변경하게 되었습니다.
우선, FAISS의 역할은 Numpy가 똑같이 수행할 수 있냐?? 라는 의문이 있었고, 그래서 작은 실험을 하나 진행했습니다.
실험: FAISS vs Numpy 유사도 검색 속도 비교
물론, FAISS가 빠르긴 한데, 아래 결과를 보시면 0.005초 차이로 문제가 전혀 안되는 수준이기에, 굳이 FAISS를 쓸 필요가 없다고 판단했습니다.
성능 비교 결과 (Top-5 검색)
| 방법 | 소요 시간 | 속도 순위 |
|---|---|---|
| FAISS | 0.002095 초 | 🥇 1위 |
| Numpy (Pure Python) | 0.007358 초 | 🥈 2위 |
| Scikit-learn (Brute Force) | 0.023916 초 | 🥉 3위 |
상세 결과
[A] FAISS
- 소요 시간: 0.002095 초
- 인덱스:
[0, 160, 2260, 1256, 307] - 거리값 (L2):
[0.0, 0.364, 0.397, 0.413, 0.415]
[B] Scikit-learn (Brute Force)
- 소요 시간: 0.023916 초
- 인덱스:
[0, 160, 2260, 1256, 307] - 거리값 (L2):
[0.0, 0.603, 0.630, 0.643, 0.644]
[C] Numpy (Pure Python)
- 소요 시간: 0.007358 초
- 인덱스:
[0, 160, 2260, 1256, 307] - 거리값 (Squared L2):
[0.0, 0.364, 0.397, 0.413, 0.415]
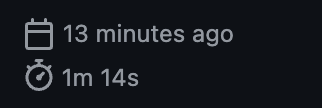
Github Actions 시간 단축
워크플로우 실행 시간
거의 1분 가까이 단축되었기에 잘한 선택이었다고 생각합니다.
Before

After
마치며
그럼 남은 작업들은 전에 작성한 글에서 말했던 아래 4가지 + 사용해보면서 수정하기.
- 초기 환경변수 설정을 하지 않고 사용할 수 있도록(?)
- 다른 사람들이 사용할 수 있도록 형태로 구축(?)
- 구축한 Leetcode 문제들을 성장하는 나무 형태로 시각화 -> 문제를 풀면 나무가 자라고, 푼 문제는 빛이 나는 잎사귀 형태(?), 난이도에 따라 다른 색깔로 표현
- 그래프 네트워크 시각화
댓글