알고리즘 RAG 개발 과정 및 결과물
깃허브 링크 : https://github.com/Hun-Bot2/Algorithm-RAG-Engine
이전 글에서 이어집니다.
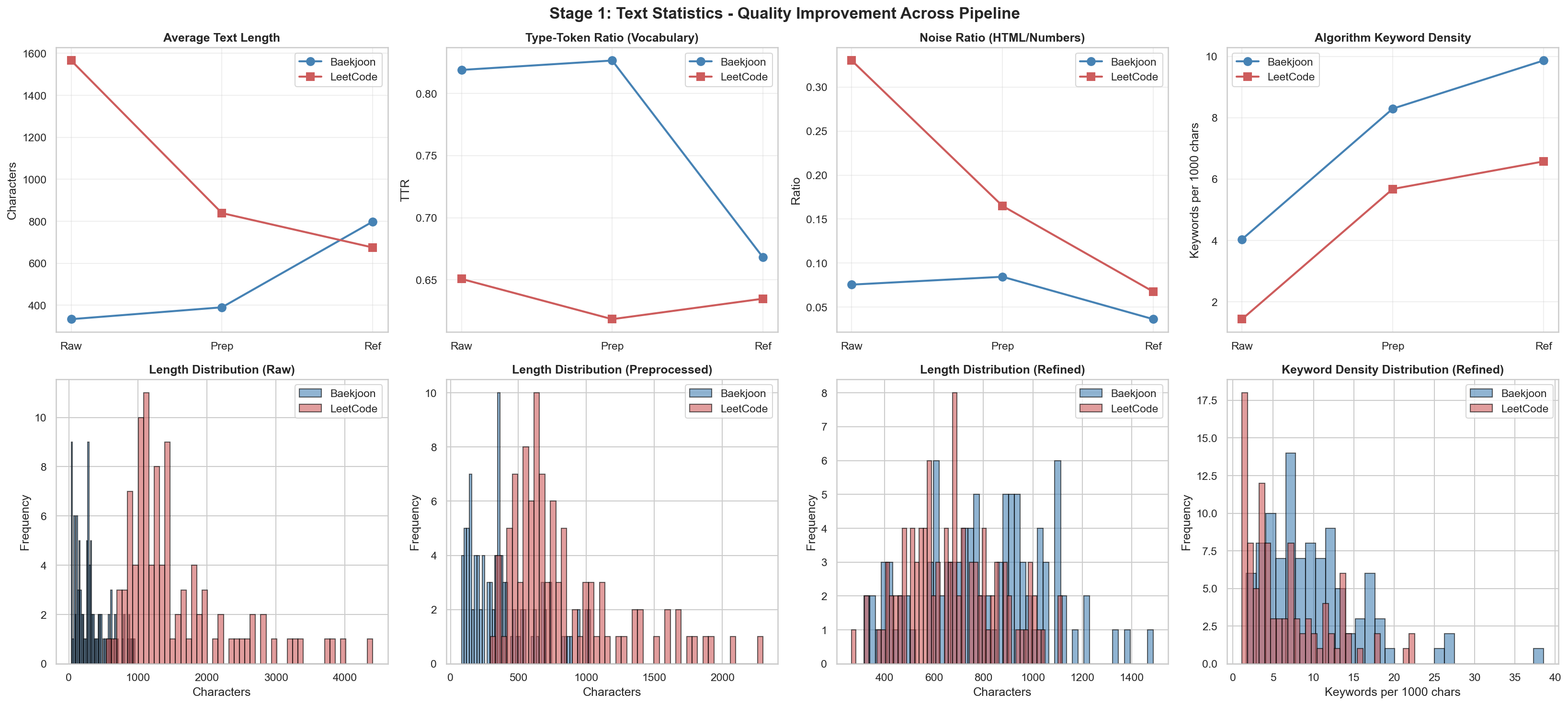
Refined 이후 결과
이전
이후
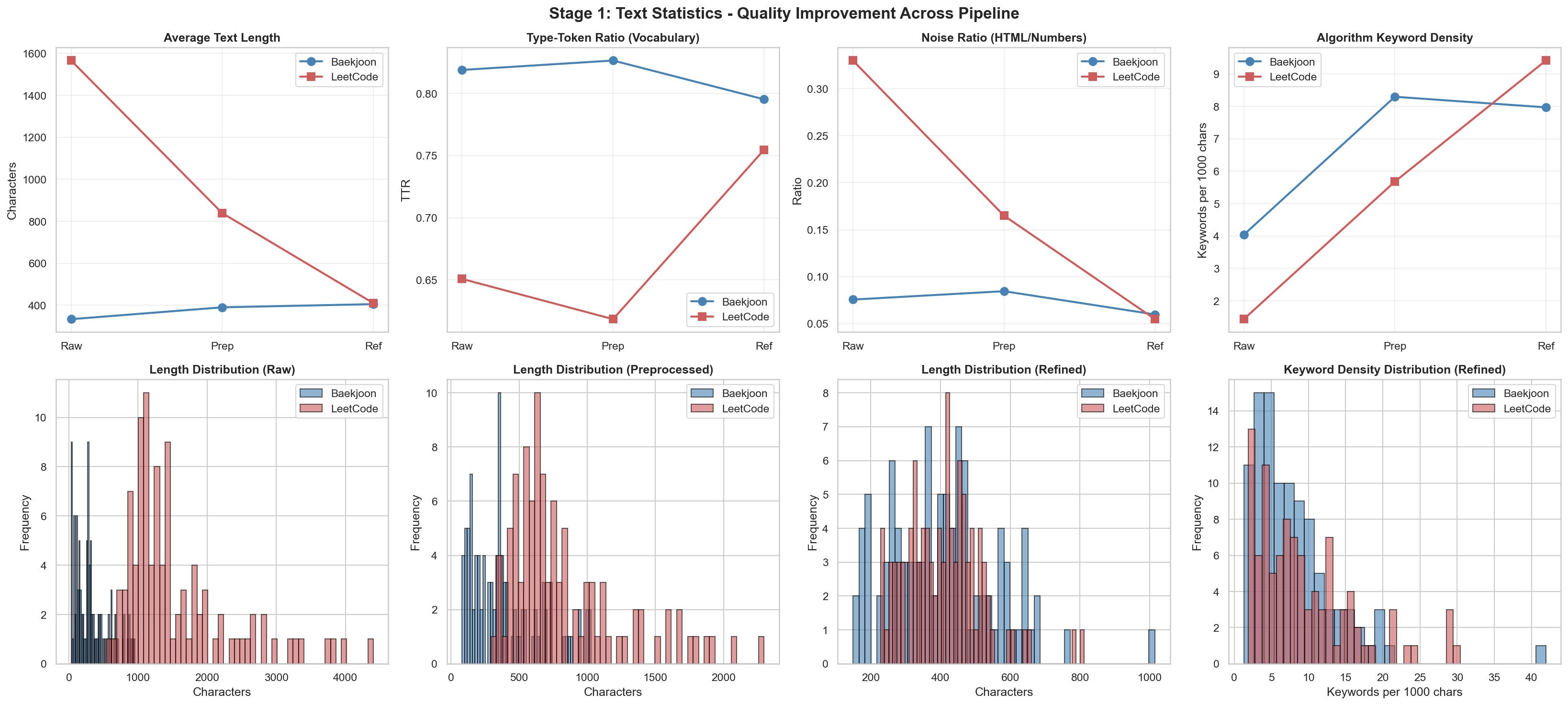
이전
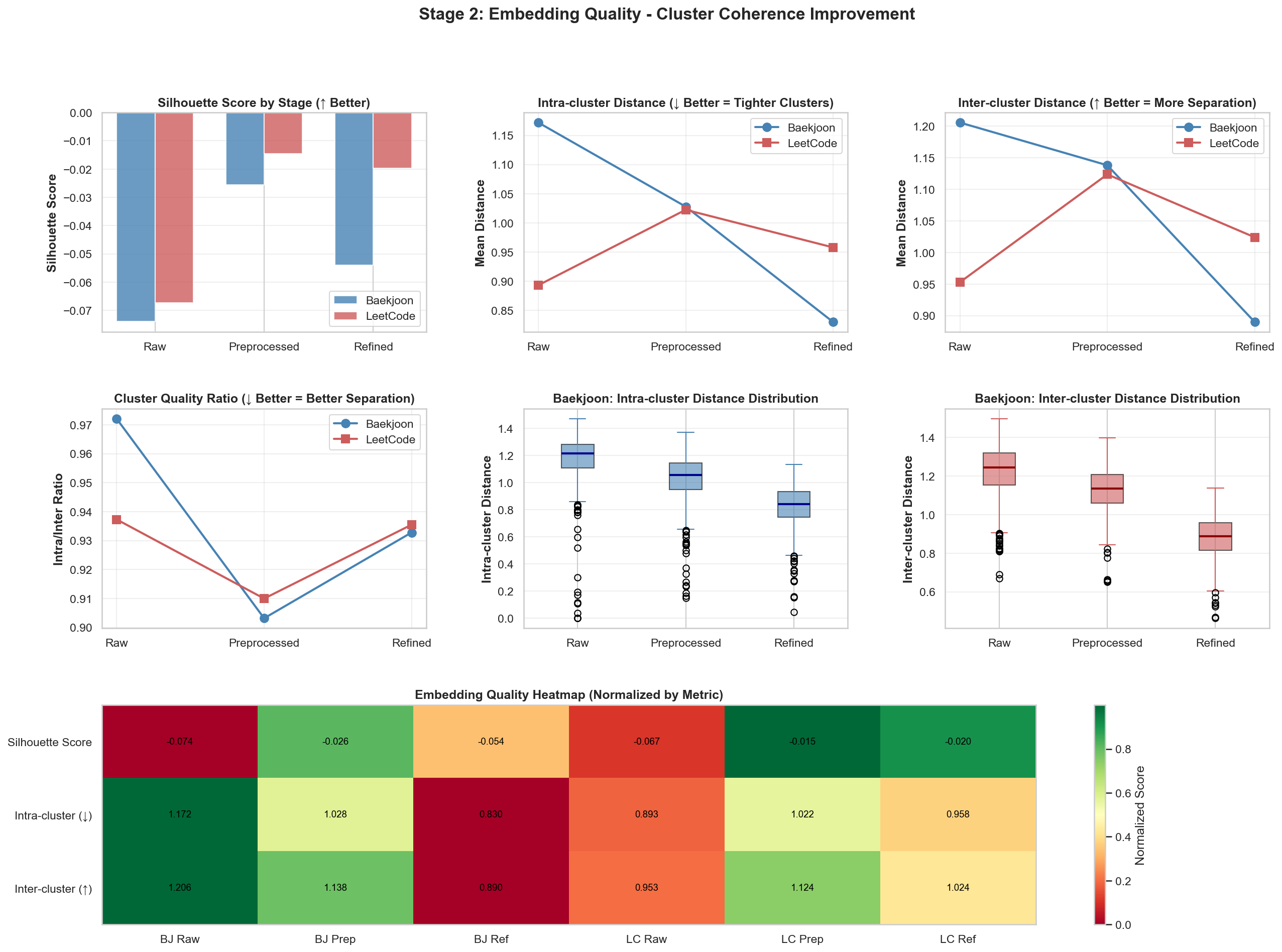
이후
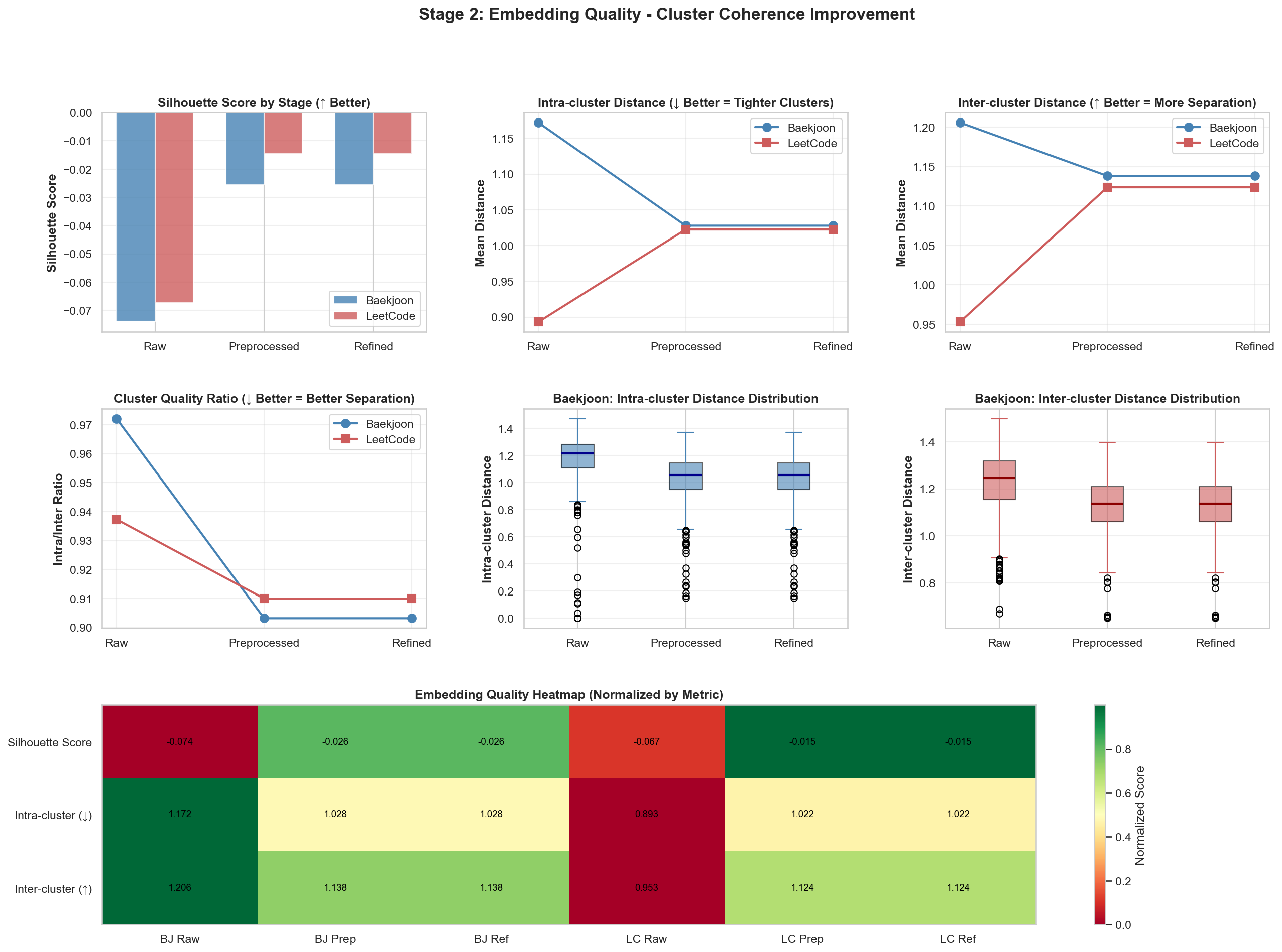
위 2개에서 눈에 띄는 변화가 있었고, 결과 값은 비슷비슷해서 다른 결과 값은 해당 repo에 가면 확인하실 수 있습니다.
자, 이제 기본적으로 embedding을 학습해봤으니, 실제 3000개의 Leetcode 문제를 넣어서 RAG 시스템을 구축해보겠습니다.
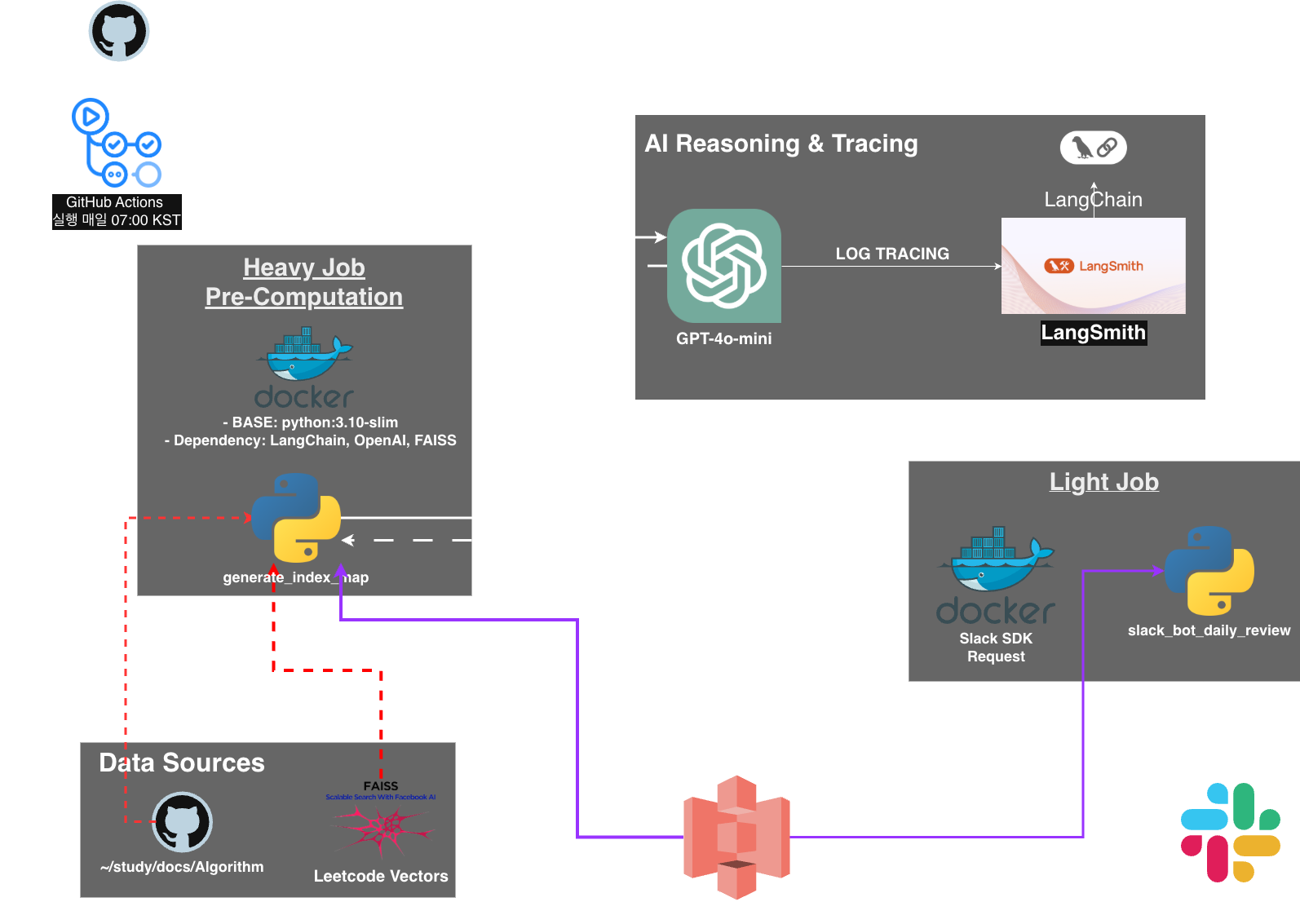
LangChain FAISS를 활용한 RAG 시스템
기존 계획이었던 Pinecone을 활용한 RAG 시스템 구축에서 방향을 바꿔, LangChain의 FAISS를 활용한 RAG 시스템을 구축하기로 했습니다.
왜 Pinecone 대신 LangChain FAISS를 선택했나면 -> Leetcode의 문제 수가 3,000 정도 밖에 안되기 때문에, Pinecone을 사용하는 것 보다는 LangChain의 FAISS를 사용하는 것이 더 효율적이라고 생각했습니다.
추가로, 기존에 개인 Study Repo에 붙어있던 Slack Bot을 분리해서 RAG Repo에 합쳤습니다. Mono Repo로 구축하려고 했는데, 추후 확장가능성을 고려해서 따로 Repo를 만들어서 관리하기로 했습니다.
전체 아키텍처는 이전 글에서 설명했고, 제 Github Repo에 자세한 설명이 있으므로 이번 글에서는 왜? 를 중심으로 설명하고, 제가 겪었던 문제들을 풀어보려고 합니다.
아키텍쳐는 위와 같습니다. FAISS를 어디서 썼냐? -> Leetcode의 문제들을 받아, 임베딩 벡터로 변환한 후, FAISS Index에 저장하고, Github Repo에 Package 형태로 올려뒀습니다.(Release에도 있으니 참고하세요)
왜 FAISS를 썼냐?
우선, 제가 모은 Leetcode 문제는 약 3,000개 정도(무료 문제만)였고, 문제들을 저장한 형태가 jsonl 파일이였습니다. 당연하겠지만? LLM이 이 문제를 다 긁어서 유사한 문제를 찾는 것은 비효율적입니다. “검색”을 위해서는 이를 벡터화해서 저장할 공간이 필요했고, 로컬 vector DB를 찾아봤습니다.
| 구분 | FAISS | ChromaDB | LanceDB |
|---|---|---|---|
| 작동 아키텍처 | In-memory / Library | SQLite 기반 DB | Arrow 기반 Serverless |
| 데이터 규모 | 대규모(10^6 이상) 최적화 | 소~중규모 적합 | 중~대규모 적합 |
| 메타데이터 필터링 | 기본 기능 약함 (수동 구현) | 매우 강력하고 쉬움 | 효율적인 필터링 지원 |
| 배포 용이성 | 바이너리 파일 하나로 끝 | DB 파일 구조 관리 필요 | 별도 파일 관리 필요 |
| 검색 속도 | 최상 (Low-level 최적화) | 보통 (SQLite 오버헤드) | 상 (Zero-copy 읽기) |
ChromaDB: SQLite를 엔진으로 사용하는 오픈소스 벡터 저장소입니다. 파이썬 네이티브 환경에서 사용이 매우 간편하며, 메타데이터 필터링 기능이 강력합니다.
LanceDB: Apache Arrow 포맷을 기반으로 하며, “서버리스(Serverless)“를 지향합니다. 디스크 IO 효율이 극도로 높아서 데이터가 커져도 성능 저하가 적습니다.
FAISS (Facebook AI Similarity Search): Meta(구 Facebook)에서 개발한 고성능 유사도 검색 라이브러리입니다. DB라기보다는 알고리즘 라이브러리에 가까우며, 메모리 내 검색 속도가 압도적입니다.
데이터가 적은데 왜 FAISS를 썼냐?
- Langchain 공부하던 중에 써보고 싶어서 사용했습니다.(블로그 3편을 참고하시면 됩니다.)
- Github Actions에 적합한 벡터 DB가 필요했고, FAISS는 단순한 라이브러리 형태로 인덱스 파일(.faiss)만 관리하면 되기에
- 구축해둔 문제는 추가 빈도가 낮기에 한 번 구축해두면 Read만 위주로 사용합니다. 그래서 속도가 빠른 FAISS를 선택했습니다.
왜 S3를 아티팩트 저장소로 썼는가? (vs GitHub Artifacts)
문제: GitHub Actions 자체에도 파일을 저장하는 기능(Artifacts)이 있는데 왜 굳이 AWS S3를 썼을까?
- 데이터 영속성: GitHub Artifacts는 일정 기간(기본 90일) 후 삭제되지만, S3는 영구 보관이 가능합니다.
- **작업 간 디커플링:**Heavy Job과 Light Job의 실행 환경을 물리적으로 격리하여 시스템 유연성을 확보했습니다. S3를 중간 매개체(Intermediary)로 활용해 데이터를 넘기고 받는 과정의 결합도를 낮춤으로써, 각 작업이 서로의 상태에 종속되지 않고 독립적으로 실행될 수 있는 구조가 필요했습니다.
- 외부 확장성: 나중에 슬랙 외에 웹 대시보드 등을 만들 때도 S3의 데이터를 API로 바로 불러올 수 있는 확장성을 고려했습니다.
Decoupling Heavy & Light Jobs
- Heavy Job: Leetcode 문제를 수집하고, 임베딩 벡터을 생성한 후, FAISS 인덱스를 구축합니다. 이 작업은 시간이 오래 걸리며, 자주 실행되지 않습니다.
- Light Job: FAISS 인덱스를 불러와서 유사한 문제를 검색하고, 유사한 문제와 llm으로 생성한 이유를 슬랙으로 전송합니다. 이 작업은 자주 실행되며, 빠른 응답이 필요합니다.
!! 변경사항
알고리즘을 풀고, 커밋하면 -> 일정 설정해둔 복습 주기마다 알림이 왔는데 -> 매일 2~3문제 학습 + 2~3문제 복습을 한다고 가정한다면 -> 1일차에는 2문제 + 2문제, 2일에 문제를 또 풀면 2문제 + 2문제 -> 3일차에는 총 6문제 + 2문제(학습)이 되는데 솔직히 감당할 수 없을 것이라고 판단되어 복습 주기를 제거했습니다.
그리고 아래와 같은 형태로 변경했습니다.
-
Trigger: 내가 오늘(또는 어제) 문제를 풀고 커밋했을 때만 작동.
-
Action:: “내가 방금 푼 이 백준 문제”와 가장 유사한 LeetCode 문제를 추천.
-
Goal: 학습한 개념을 다른 플랫폼(LeetCode) 문제에 적용하여 체화하는 것으로 목표 변경.
해당 Repo의 최신 커밋만 가져오도록 하는 gitpython 도입
이건 뭐 구조상 매번 모든 파일을 다 가져오면 비효율적이고, 최신 커밋에서 변경된 파일만 가져오도록 했습니다.
def get_latest_changed_files(repo_path: str, target_subdir: str) -> List[str]:
"""
Detects files changed in the latest commit (HEAD) within the target subdirectory.
"""
print(f"[INFO] Checking git history in: {repo_path}")
changed_files = []
try:
repo = Repo(repo_path)
# Ensure we have commits to compare
if not repo.head.is_valid():
print("[WARN] No valid HEAD found (empty repo?). Scanning all files.")
return get_all_files(repo_path, target_subdir)
head_commit = repo.head.commit
# If no parents (first commit), scan all files in the tree
if not head_commit.parents:
print("[INFO] First commit detected. Scanning all files.")
for item in head_commit.tree.traverse():
if item.path.startswith(target_subdir) and item.path.endswith((".md", ".mdx")):
full_path = os.path.join(repo_path, item.path)
changed_files.append(full_path)
else:
# Compare HEAD with HEAD~1 (Previous commit)
parent = head_commit.parents[0]
diffs = parent.diff(head_commit)
for diff in diffs:
# We only care about added (A) or modified (M) files
# diff.b_path is the new path. If deleted, it might be None or verify deleted_file flag
if diff.b_path and not diff.deleted_file:
if diff.b_path.startswith(target_subdir) and diff.b_path.endswith((".md", ".mdx")):
full_path = os.path.join(repo_path, diff.b_path)
changed_files.append(full_path)
except Exception as e:
print(f"[ERROR] Git processing failed: {e}")
print("[INFO] Falling back to scanning all files.")
return get_all_files(repo_path, target_subdir)
return changed_filesLeetcode 문제끼리는 중복해서 가져오지 않도록 하는 Python로직 추가
# Search
search_limit = MAX_RECOMMENDATIONS + 2 # Buffer to avoid self-match
docs_and_scores = vectorstore.similarity_search_with_score(
user_prob["query_text"],
k=search_limit
)
recs = []
# Avoid Duplicates & Self-Match
seen_title= set()
user_title_clean=re.sub(r'[^a-zA-Z0-9가-힣]', '', user_prob["title"].lower())
for doc, score in docs_and_scores:
if len(recs) >= MAX_RECOMMENDATIONS:
break
rec_title=doc.metadata.get("title", "Unknown")
rec_title_clean=re.sub(r'[^a-zA-Z0-9가-힣]', '', rec_title.lower())
if user_title_clean in rec_title_clean or rec_title_clean in user_title_clean:
continue # Skip self-match
if rec_title_clean in seen_title:
continue # Skip duplicates
seen_title.add(rec_title_clean)
...알림(실제 응답)
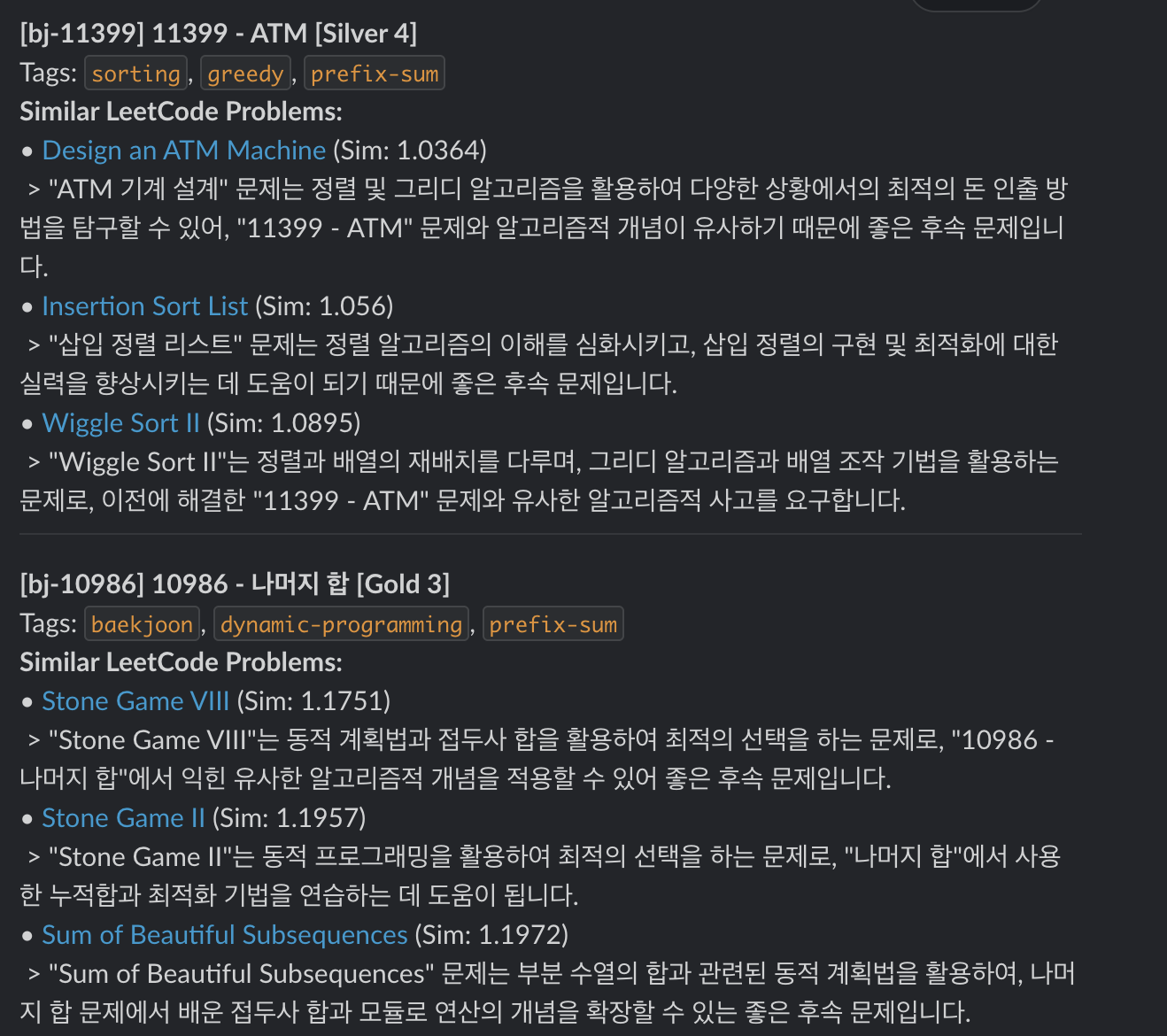
마치며
이로써 알고리즘 RAG 시스템 구축이 완료되었습니다. 이번 프로젝트를 통해 벡터 검색 기술과 RAG 시스템의 실제 적용 방법을 이해할 수 있었습니다. 여기서 추가할 부분들은 아래 1~4번 정도가 될 것 같습니다.
- 초기 환경변수 설정을 하지 않고 사용할 수 있도록(?)
- 다른 사람들이 사용할 수 있도록 형태로 구축(?)
- 구축한 Leetcode 문제들을 성장하는 나무 형태로 시각화 -> 문제를 풀면 나무가 자라고, 푼 문제는 빛이 나는 잎사귀 형태(?), 난이도에 따라 다른 색깔로 표현
- 그래프 네트워크 시각화
앞으로 제가 사용해보면서 지속적으로 시스템을 개선하고, 더 많은 문제를 추가하여 알고리즘 학습에 도움을 줄 수 있는 도구로 발전시켜 나가겠습니다. 감사합니다!
댓글