
알고리즘 RAG 개발 과정 및 모델 성능 비교
이전 글에서 이어집니다.
Architecture
기존에 생각했었던, 전체 흐름입니다.

본격적인 개발에 앞서 공부할 겸, 임베딩 모델을 비교해보기로 했습니다.
생각보다 시간이 꽤 걸리는 작업이였고, 제가 한 분석이 맞는지 모르겠어서 커뮤니티에 검증을 받겠지만, 혹시 이 글을 읽으셨다면 피드백 주시면 감사하겠습니다!
데이터 수집 및 전처리 (Data Acquisition and Preprocessing)
-
LeetCode : Leetcode GraphQL API를 통해 2025년 기준 전체 문제셋(약 3,500개 이상)
-
Baekjoon : solved.ac API 및 웹 크롤링
각각 100개의 데이터를 수집했고, 수집된 데이터는 임베딩 성능을 극대화하기 위해 다음과 같은 전처리 과정을 거쳤습니다.
-
HTML 및 노이즈 제거: HTML 태그와 불필요한 서술어를 정제했습니다.
-
검색 최적화 텍스트 구성: Title, Tags, Content를 결합하여 모델이 문제의 카테고리와 제약 조건을 명확히 인지할 수 있도록
embedding_text필드를 생성했습니다. -
Logical Skeleton: (AI가 이 말을 겁나게 좋아합니다) 문제의 핵심 알고리즘 논리를 요약한
logical_skeleton필드를 LLM을 활용해 생성했습니다(백준은 한국어 기반이기에 영어로 번역한 내용을 담았습니다)
1. 데이터 수집 (Data Collection)
├─ baekjoon_data_collection.py → baekjoon_raw_data.jsonl (100개)
└─ leetcode_data_collection.py → leetcode_raw_data.jsonl (100개)
2. 데이터 전처리 (Preprocessing)
├─ preprocess.py → *_preprocessed.jsonl
│ └─ HTML/마크다운 제거, 핵심 로직 추출
└─ refine_leetcode.py → leetcode_refined.jsonl
└─ LLM 기반 논리 골격(Logical Skeleton) 추출
3. 데이터 정규화 (Normalization)
├─ improve_recall.py → baekjoon_refined.jsonl
│ └─ 백준 데이터도 영문 논리 골격으로 변환(여기서 Logical Skeleton 태그가 달림)
└─ data_normal.py → baekjoon_normalized.jsonl
└─ 접두사("Logical Skeleton: ") 제거 -> "embedding_text"로 변환
4. Ground Truth 구축 (GT Creation)
├─ ground_truth_finder.py → potential_gt.json
│ └─ LLM으로 후보 자동 추출하고 검수
└─ leetcode_match_pgt.py → ground_truth_v2.json
└─ 100세트 BJ-LC 정답 쌍 완성
5. 모델 평가 (Model Benchmarking)
├─ evaluate_model.py → OpenAI text-embedding-3-small
├─ evalute_model_ver2.py → Jina-v3 (1024 dim)
└─ evalute_model_ver3.py → BGE-M3 (Local)
└─ Recall@K, MRR 측정왜 100개만 했냐?
Ground Truth를 100개 만들었기에, 랜덤으로 100개씩 뽑아서 실험을 진행했습니다. 보통 Gloden Set(?)이라고 하는 것 같더라구요. 이건 사람이 직접 매핑해야한다고 합니다.
임베딩 모델 비교 및 검증 (Embedding Model Benchmark)
가장 정교한 지식 매핑을 위해 세 가지 주요 임베딩 모델을 대상으로 성능 검증(Pilot Test)을 수행했습니다.
비교 모델: Jina v3, OpenAI text-embedding-3-small, BGE-M3.
평가 지표 (Metrics)
- Recall@K: 상위 K개의 결과 중 정답이 포함된 비율.
- MRR (Mean Reciprocal Rank): 정답이 나타난 순위의 역수 평균.
벤치마크 결과 (100-Set Golden Set 기준)
| Model | Recall@1 | Recall@5 | Recall@10 | MRR |
|---|---|---|---|---|
| OpenAI-v3 (small) | 0.22 | 0.50 | 0.65 | 0.354 |
| Jina-v3 (1024 dim) | 0.17 | 0.47 | 0.63 | 0.319 |
| BGE-M3 (Local) | 0.15 | 0.40 | 0.53 | 0.272 |
OpenAI-v3(small) 모델이 가장 우수한 성능을 보였습니다.
Recall@10 : 정답 후보군을 10위 안에는 잘 가져오는데, Recall@1 : 1위에 정답을 맞추는 비율이 상대적으로 낮음 (22%)
이렇게 끝냈으면 좋았겠지만…
사실 이 결과를 보고 나서도 뭔가 찜찜한 느낌이 들었습니다. 내가 뽑아낸 데이터는 3개인데 [RAW, Preprocessed,Refined] 그냥 이렇게만 해도 될까? 라는 의문이 들었습니다.
그래서, 제가 한 과정 전체를 분석해보기로 하고 다음과 같은 추가 실험을 진행했습니다. 데이터 저장방식은 .jsonl로 했습니다.
[1] Text Statistics: Length, TTR, noise ratio, keyword density
[2] Embedding Quality: Intra/inter-cluster distances, Silhouette Score
[3] t-SNE & UMAP
[4] Cross-lingual Alignment: KR <-> EN
[1] Text Statistics
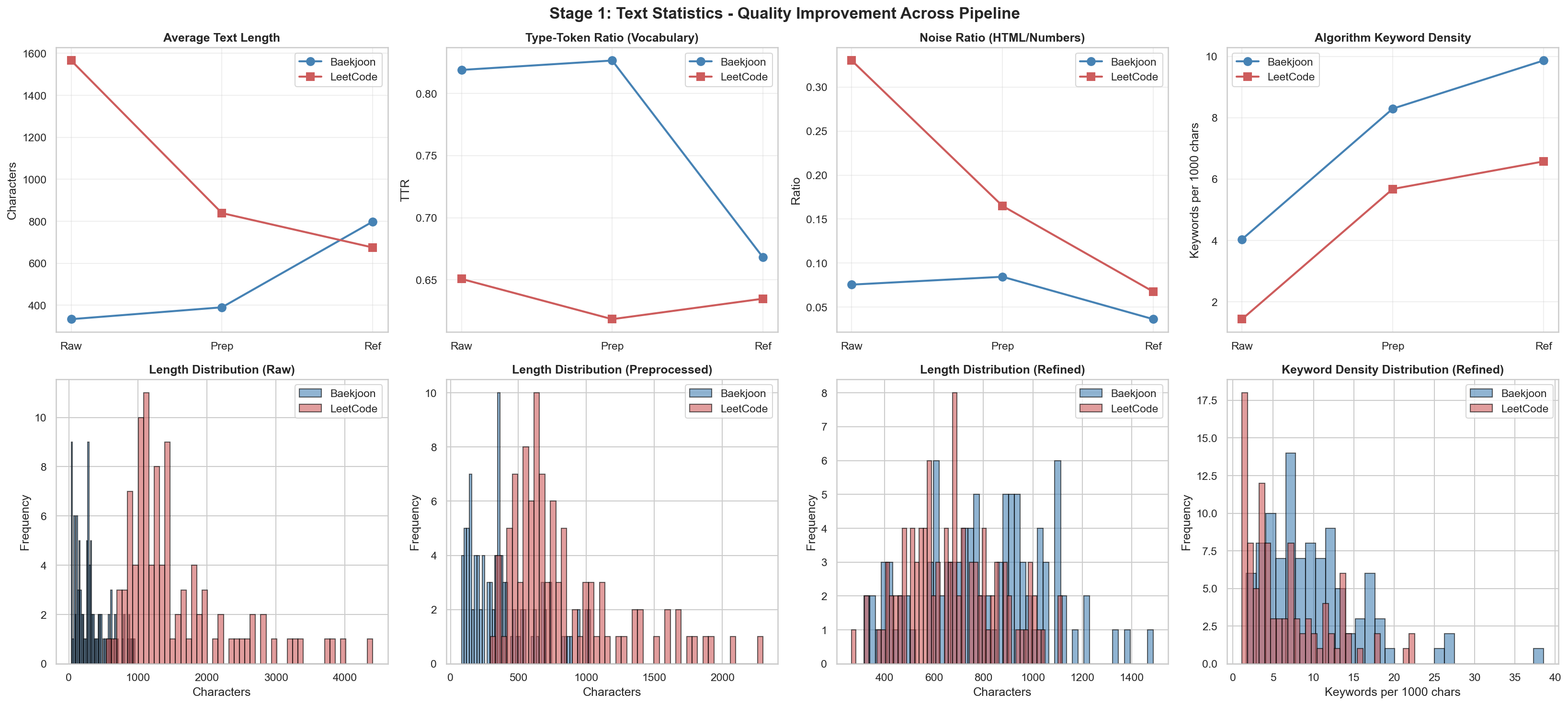
HTML Noise부분에서 차이가 나는 이유? leetcode는 graphql api를 통해 그대로 뽑아오는 로직을 사용했고
{"id": "14", "title": "Longest Common Prefix", "titleSlug": "longest-common-prefix", "difficulty": "Easy", "content": "<p>Write a function to find the longest common prefix string amongst an array of strings.</p>\n\n<p>If there is no common prefix, return an empty string <code>""</code>.</p>\n\n<p>&n"}백준은 solved.ac api를 통해 뽑아왔는데
{"id": "9251", "title": "LCS", "difficulty": 11, "tags": ["dp", "string", "lcs"], "content": "LCS(Longest Common Subsequence, 최장 공통 부분 수열)문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다.예를 들어, ACAYKP와 CAPCAK의 LCS는..."}백준에는 HTML 태그가 거의 없어서 노이즈 비율이 낮게 나온 것 같습니다. 그래서 같은 전처리 코드를 돌렸을 때는 오히려 백준 데이터가 조금 올라가는 현상이 발생한게 아닐까 추측됩니다.
[2] Embedding Quality
Jina-v3와 OpenAI-v3(small) 모델로 각 파일마다 임베딩을 생성했습니다. 사용량은 뭐 얼마 안나왔습니다.
BAEKJOON DATASETS:
Raw: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Preprocessed: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Refined: 100 items | Fields: ['id', 'title', 'difficulty', 'tags', 'content', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
LEETCODE DATASETS:
Raw: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Preprocessed: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']
Refined: 100 items | Fields: ['id', 'title', 'titleSlug', 'difficulty', 'content', 'tags', 'content_cleaned', 'embedding_text', 'embedding', 'embedding_model', 'embedding_dim', 'embedding_jina', 'embedding_jina_model', 'embedding_jina_dim', 'embedding_openai', 'embedding_openai_model', 'embedding_openai_dim']Silhouette Score
K-Means와 같은 Clustering 알고리즘을 사용하여 데이터를 그룹화 할 때, 그룹이 잘 분류가 되었나?? 확인하는 방법 중에 하나.
이는 [-1~1] 까지의 값을 가지는데, 제 프로그램의 목적은 Baekjoon 문제에서 Leetcode 문제를 잘 매칭하는 것이기에 이 되는, 백준 문제들끼리의 거리(a) > 백준 문제와 leetcode 문제간의 거리(b) 가 되도록 하는 것이 목표이고, 그래서 음수가 나오는게 좋습니다.
- (Intra-cluster distance): 내가 속한 군집 내 다른 데이터들과의 평균 거리입니다.
- (Inter-cluster distance): 내가 속하지 않은 가장 가까운 군집과의 평균 거리입니다.
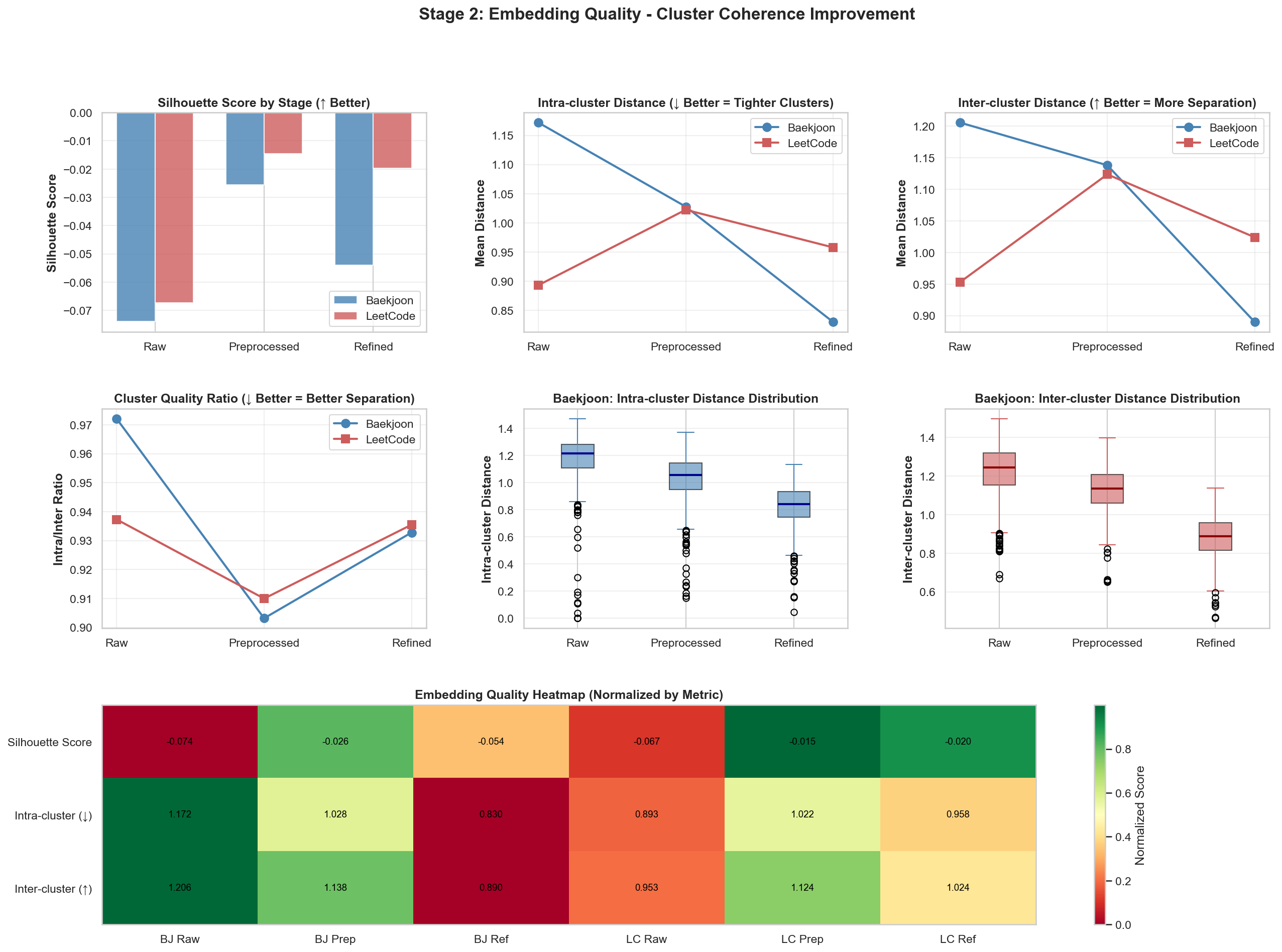
1.Silhouette Score
Raw -> Preprocessed로 갈 때, 가장 큰 향상이 있었고, Refined로 갈 때는 오히려 감소하는 모습을 보여줬습니다. 이는 전처리 과정이 임베딩 품질에 가장 큰 영향을 미쳤음을 보여줍니다.
2. Intra-cluster Distance (군집 내 거리)
군집 내부의 데이터들끼리 얼마나 가까운지를 측정합니다. 값이 낮을수록 같은 카테고리의 문제들이 벡터 공간에서 촘촘하게 잘 모여 있다는 뜻입니다.
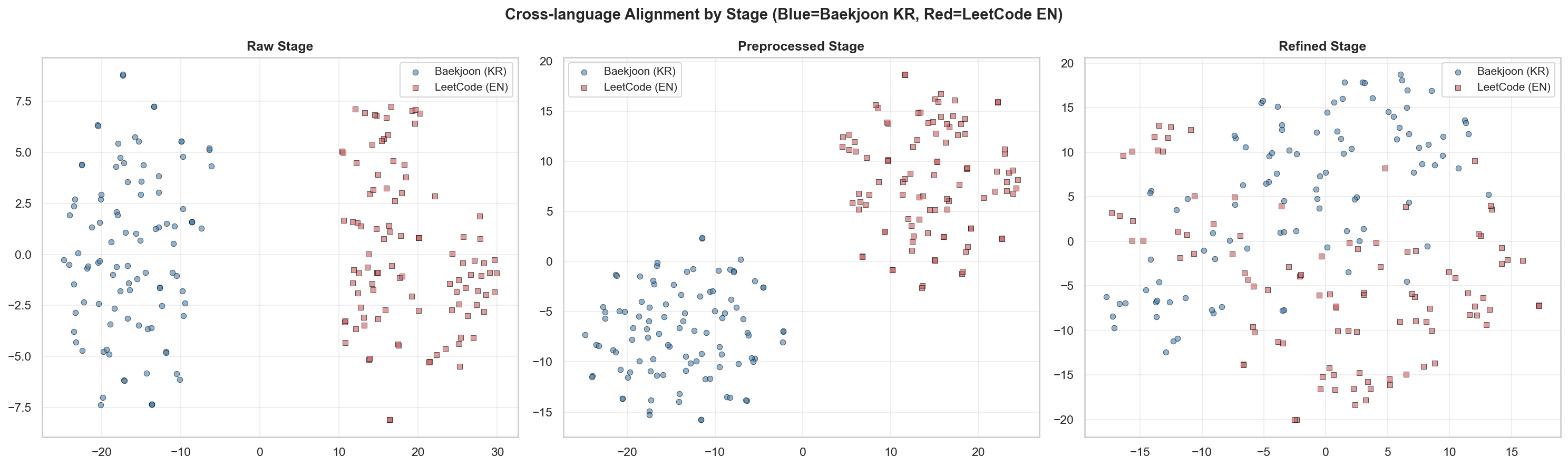
백준(파란색)은 Raw에서 Refined로 갈수록 거리가 급격히 감소합니다. 이는 정제 과정을 거치며 백준 문제들이 서로 일관성 있는 벡터 표현을 갖게 되었음을 의미합니다. 반면 리트코드는 Preprocessed에서 정점이 찍혔다가 다시 낮아지는 양상을 보입니다.
3. Inter-cluster Distance (군집 간 거리)
서로 다른 군집(백준 그룹 vs 리트코드 그룹) 사이의 거리를 측정합니다. 값이 높을수록 두 그룹이 명확히 구분된다는 뜻입니다.
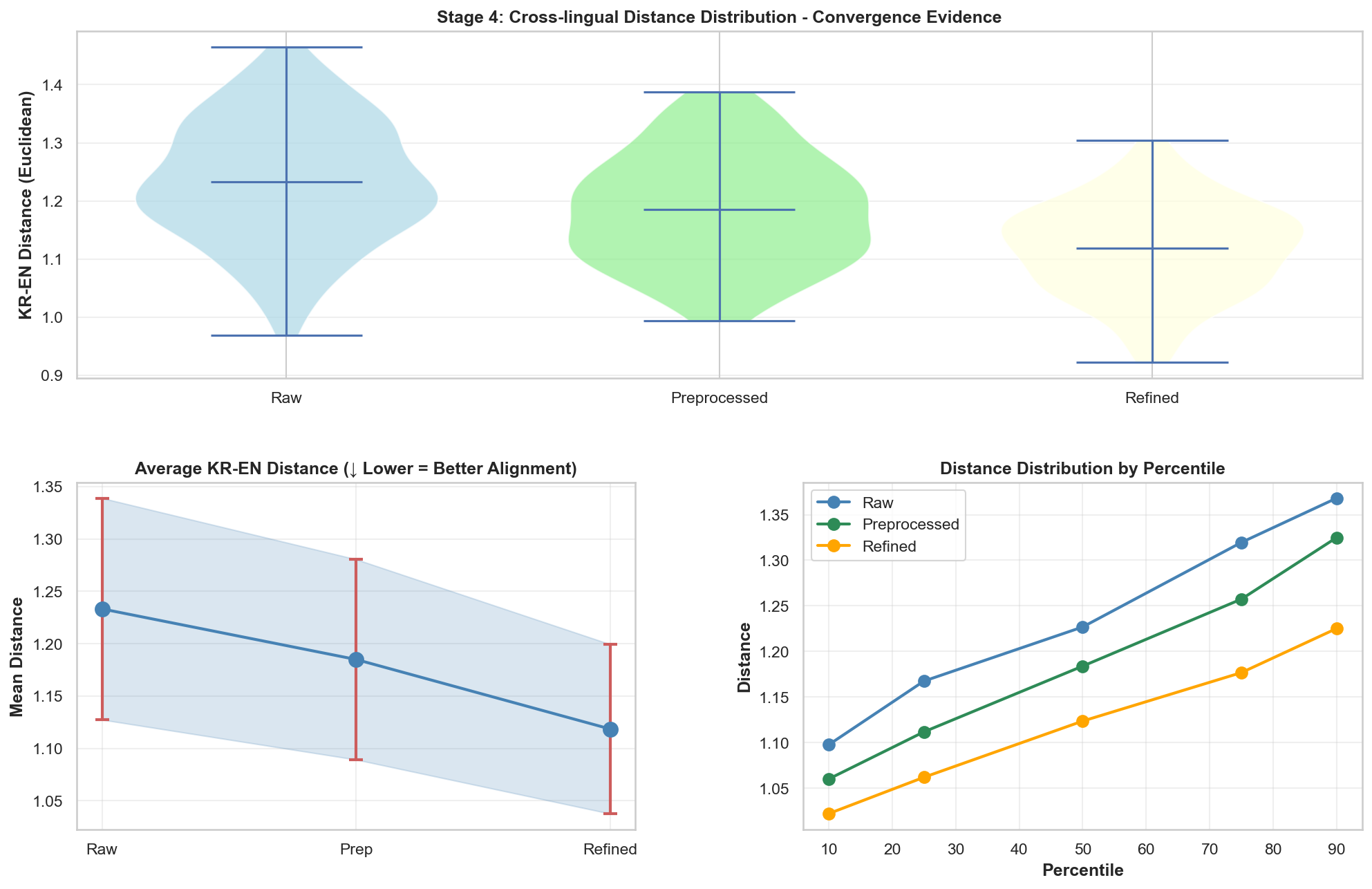
백준은 단계가 진행될수록 거리가 오히려 줄어드는데, 이는 백준 데이터가 리트코드 데이터의 벡터 영역으로 점점 가까워지고 있음을 시사합니다. 즉, 두 플랫폼 간의 ‘의미적 거리’가 좁혀지고 있다고 해석할 수 있다고 봅니다.
4. Cluster Quality Ratio (Intra/Inter Ratio)
(군집 내 거리 / 군집 간 거리)의 비율입니다. 이 값이 낮을수록 이상적인 상태입니다.
두 데이터셋 모두 Preprocessed 단계에서 최저점(가장 좋은 품질)을 찍습니다. 이후 Refined 단계에서 약간 상승하는 것은, 너무 과한 정제가 오히려 데이터의 고유한 특징을 일부 희석시켰을 가능성을 보여줍니다.
5. Distance Distribution (Box Plots)
백준 데이터의 거리 분포를 시각화한 것입니다. 중앙값(박스 안의 선)과 데이터의 퍼짐 정도를 볼 수 있습니다.
Intra-cluster: 단계가 진행될수록 박스의 높이가 낮아지고 위치가 아래로 내려갑니다. 이는 데이터들이 극단적인 이상치(Outlier) 없이 고르게 밀집되고 있음을 의미합니다.
Inter-cluster: 외부와의 거리 분포 역시 하향 안정화되며, 다른 데이터셋과의 비교가 가능한 범위 내로 들어오고 있습니다.
6. Embedding Quality Heatmap
모든 지표를 종합하여 시각화한 표입니다. 초록색에 가까울수록 해당 지표에서 우수한 성능을 보임을 뜻합니다.
**BJ Prep (백준 전처리)**과 LC Prep (리트코드 전처리) 열에서 초록색 비중이 가장 높습니다.
결과적으로 현재의 데이터셋에서는 ‘Preprocessed’ 상태의 임베딩이 검색 효율이 가장 높을 것으로 통계적 결론을 내릴 수 있습니다.
이렇게 결과가 나온 것으로 보아, Refined 단계에서 어떤 문제가 있었길래 이렇게 되었을지 확인해습니다.
역시나, 위에게 AI가 그렇게 강조하고 좋아했던 백준 데이터셋에서 ->“embedding_text”안에 Logical Skeleton으로 임베딩 텍스트를 바꿔준 것이 오히려 독이 되었고, Leetcode 데이터와 달라서 벡터 공간에서 멀어지게 된 것이 아닌가 추측됩니다.
해결 : 알고리즘 개발기 04
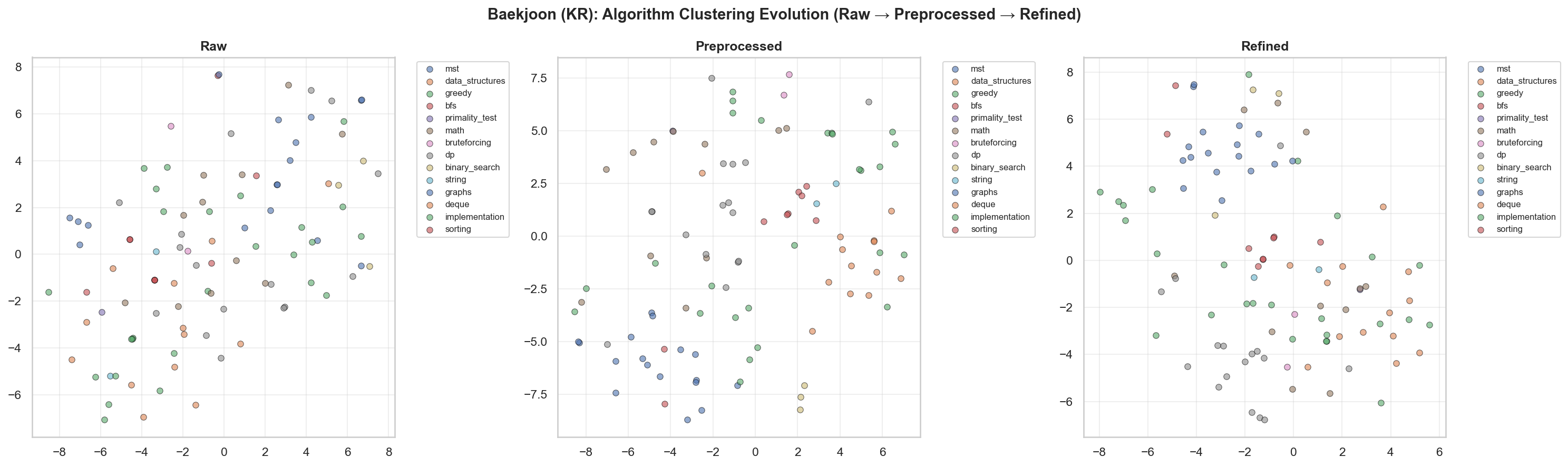
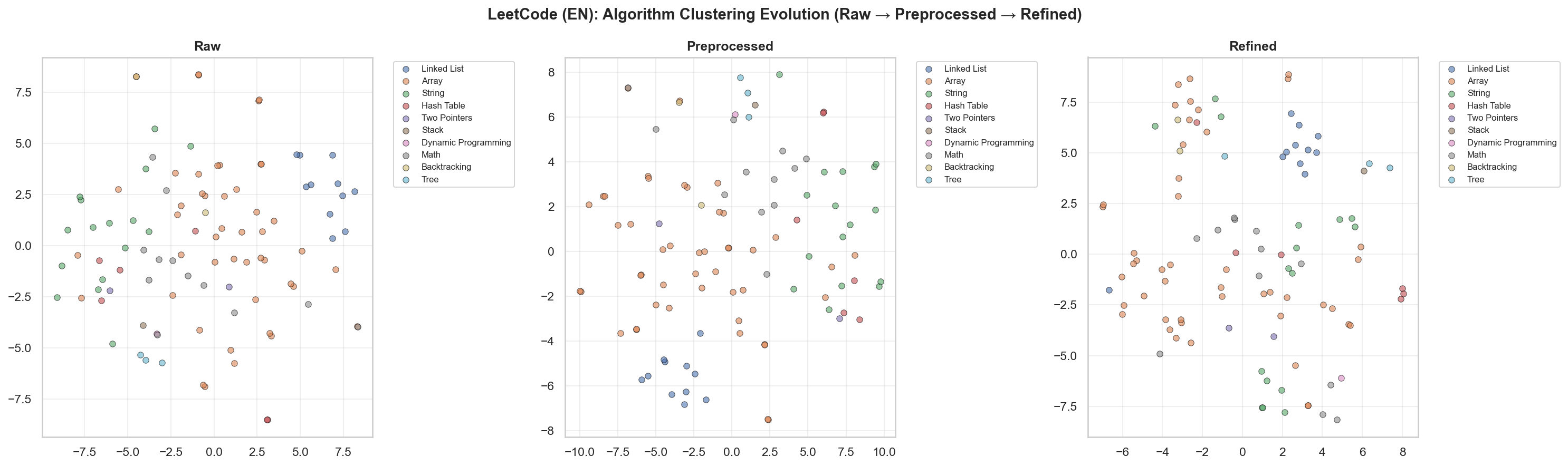
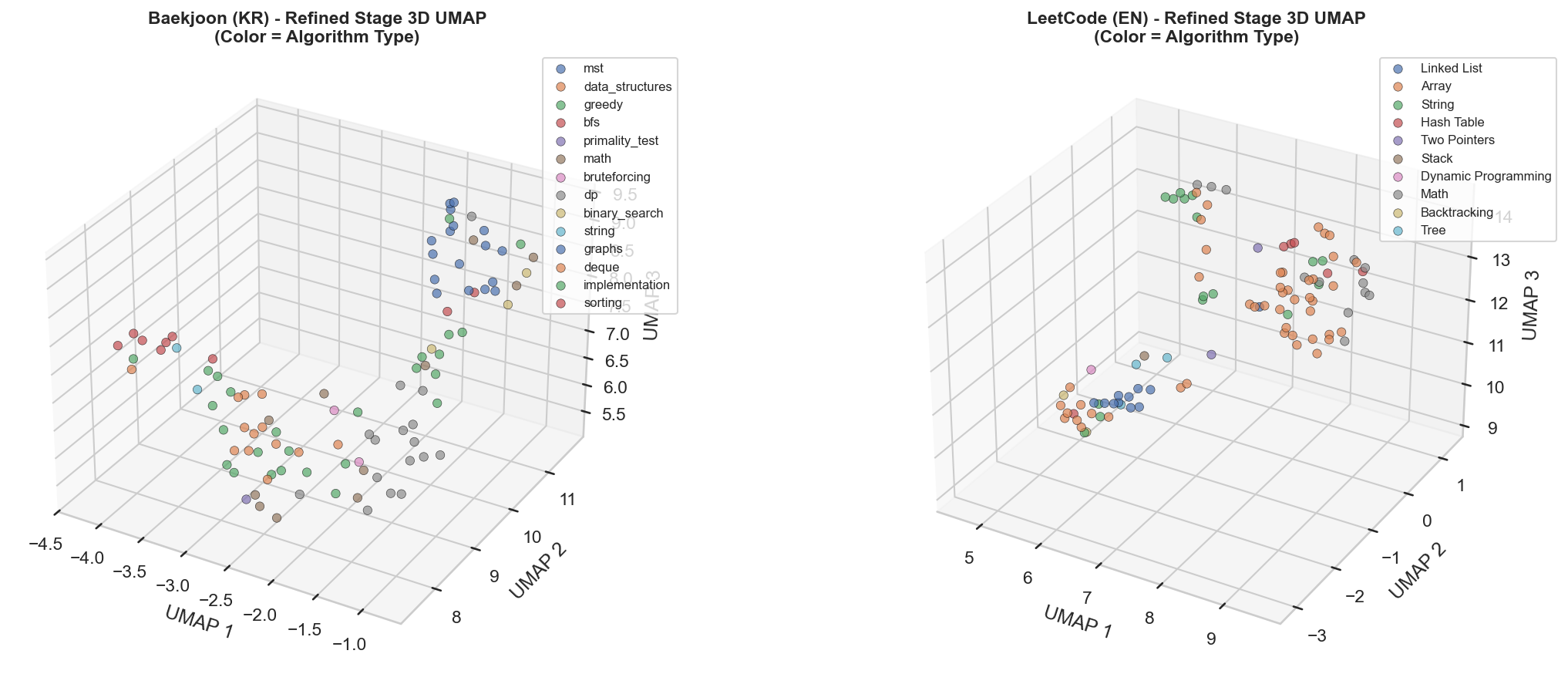
[3] t-SNE & UMAP
백준 문제 t-SNE 시각화
Leetcode 문제 t-SNE 시각화
한국어 -> 영어 전처리 과정
UMAP 시각화 (Refined 데이터셋)
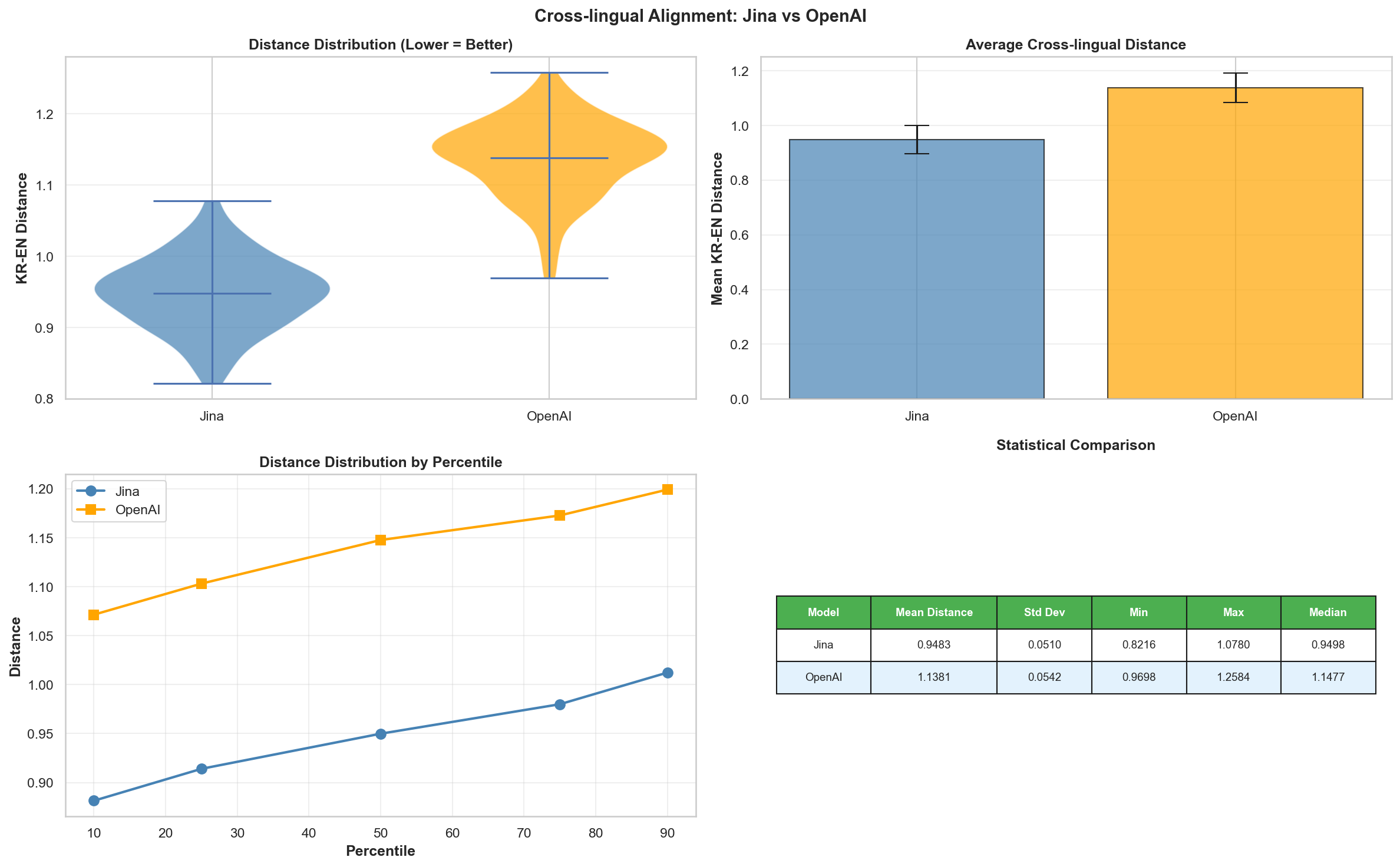
[4] Cross-lingual Alignment
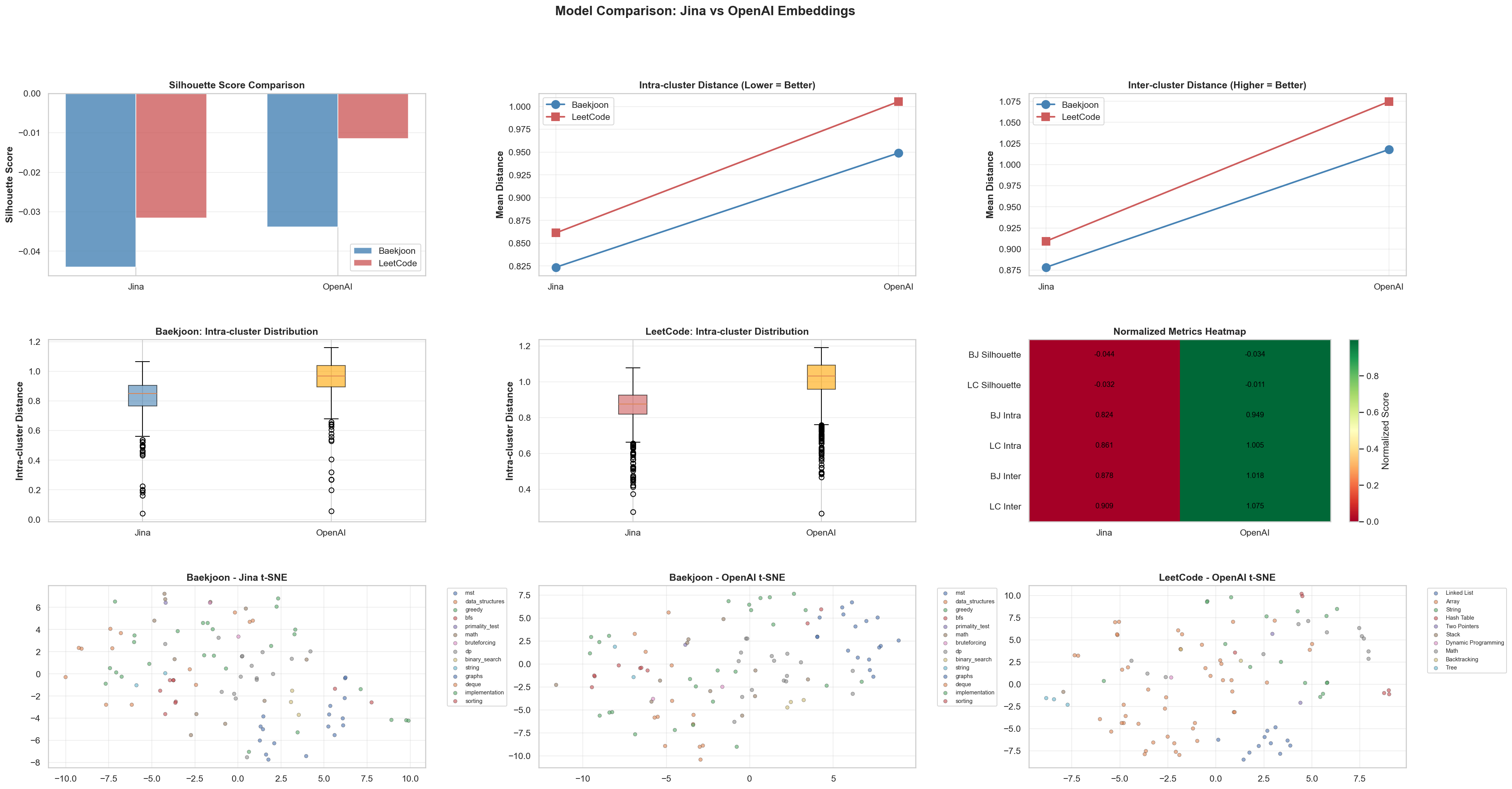
Jina v3 vs OpenAI text-embedding-3-small
위에서 작업한 전처리 과정과 분석을 바탕으로, Jina v3와 OpenAI text-embedding-3-small 모델의 성능 차이를 비교했습니다.
OpenAI 모델이 전반적으로 더 나은 성능을 보였으며, 추후 앱 개발에 OpenAI 모델을 채택하기로 결정했습니다.
결론 및 다음 단계
이번 임베딩 모델 비교 및 데이터 전처리 분석을 통해 다음과 같은 결론을 도출했습니다.
- OpenAI text-embedding-3-small 모델이 Jina v3보다 우수한 성능을 보임.
- 데이터 전처리 과정이 임베딩 품질에 큰 영향을 미침.
- Refined 단계에서의 과도한 정제가 오히려 성능 저하를 초래할 수 있음.
우선, refined 단계에서 logical skeleton을 제거하고, 두 데이터셋을 똑같이 맞춘 후, 다시 한 번 벤치마크를 돌려보려고 합니다.
[Algorithm Type] {Algorithm Name}
[Problem Summary] {Core logic description}
[Complexity] Time: {Time}, Space: {Space}
댓글